Author(s): Siva Karthik Devineni
In the ever-evolving landscape of the IT industry, data acts as the foundational element driving decisions, strategies, and innovations. The quality of data significantly influences the operational efficiency, decision-making accuracy, customer satisfaction, and overall success of IT initiatives. Poor data quality leads to erroneous insights, and ineffective strategies, and could potentially cost companies millions, making data quality improvement not just an option but a critical necessity. This paper explores the multifaceted importance of maintaining high data quality in the IT industry and outlines various strategies for improvement. It talks about big-picture methods, including sorting out data, keeping it up-to-date, using technology to improve accuracy and trustworthiness, and ensuring timeliness. This article explains methods IT specialties and groups should use to check and fix their data quality. These steps will help keep the information accurate and valuable for better results in the future.
Data quality refers to the condition of data based on factors such as accuracy, completeness, reliability, relevance, and timeliness, which collectively determine the value of the data in decisionmaking processes [1].
In IT, having good data helps make systems, apps, and processes work smoothly. This gives good information about big choices and talking with customers. Quality data is crucial to machine learning, analytics, and business success. It helps improve the results of IT projects [2].
Bad data quality can cause big problems for IT projects and businesses. This can cause wrong choices, bad processes, unhappy customers, and big money losses. Studies have shown that businesses lose $12.9 million yearly because their data could be better suited to less work and extra costs. In computer projects, poor data makes systems work poorly. This can cause projects to take longer and make users and clients not trust computer systems or reports. In the IT world, data quality problems often happen, including wrong information, lack of agreement, extra entries, missing values, and old details.
These problems come from different places, like mistakes made by people, mess-ups during system transfers, or needing to check and clean data well enough. Data problems and mistakes can happen because there are many sources and formats for it. Also, bad control of data and having rules in place can help the quality of the information. Learning about these problems is the first thing you must do to make good plans for improving data quality and using IT powers at their best [3].
Data quality is all about how good and useful the data is. It has many parts, each helping to make the data more useful and worthwhile. OR/and Data quality are many-sided and come with different features. All these parts make the data important and useful. The most common data quality measurements include markdown 1. Accuracy 2. Completeness 3. Timeliness 4. Consistency 5. Validity 6. Reliability 7. Relevance [4]:
The degree to which data correctly describes the "real-world" object or event. Accurate data correctly reflects reality
It's about how much information that's needed is available. Lacking information can cause "the absence of needed data," which is critical for making good choices.
This dimension refers to the consistency of the data across different sources and over time. Reliable data maintains its integrity throughout its lifecycle.
Data should be relevant to the context and purposes for which it is used, ensuring its applicability in decision-making processes.
Refers to data being up-to-date and available when needed. Timely data is crucial for decisions that rely on the most current information.
Each of these parts helps make data work better. Different computer users and business jobs need to do what needs to be done well [5].
The Role of Data Governance in Maintaining Data Quality Data governance is a collection of rules and steps that make sure data stays good from the start until it has finished being used. It's about taking care of data, ensuring we follow rules about data, and getting better quality data. Data management that works makes sure jobs are given to people who handle data. It identifies ways to fix problems, improve quality, and keep data safe. It is a constant watch, checking and fixing problems with data. Data cleaning, telling who gets what, and adding more detail help quickly find and fix any differences in data. These methods help manage and improve how good the data is. They make sure small mistakes don't make data a waste. They keep data important to the company [6].
Data profiling is studying and collecting information about data from a current source. This gives us stats and more details about that data. The goal is to learn about data situations by finding problems and oddities like missing details, wrong data, and irregularities [7].
Data quality checks carefully inspect data against certain rules and standards. This way, testing different data checks correctness, fullness, and other quality factors. It spots parts that do not pass quality limits [8].
This means not just finding mistakes and bad connections. It also involves fixing them by cleaning the data properly and watching how these changes improve the quality of information. Enrichment analysis adds extra details to existing data. It makes it better and more complete using extra information from different sources [9].
Getting feedback from regular users who often use the data can help us see problems with quality that we won't notice using automatic ways. User comments are important for knowing how easy and useful data quality is [10].
In data quality improvement, many tools and tech are very important. Data checking tools such as Informatica, Talend, and Data Cleaner provide strong features for looking at things like what data is about, its shape, and if it's good quality. AI (Get, Change, and Put) tools like IBM Infosphere, Oracle Data Integrator, and Microsoft SSIS include building good quality steps in their datamatching actions.
This means ensuring that data is cleaned and similar throughout the motion process. All-round software like SAS Data Quality and SAP Master Data Governance offer complete solutions. These include checking the data used and looking at whether it's clean and helpful information for the data. Often, special scripts and SQL searches are used. These helps fix and check data errors based on an organization's unique rules and needs. They go beyond regular testing. These tools and technologies give power to data analysts to keep their data very clean and improve its accuracy. They are based on big books and references on examining and making better quality data used in science [11].
A leading financial services firm faced challenges with data consistency and accuracy, impacting its reporting and decisionmaking capabilities. The firm implemented a data quality initiative that involved [12]:
Using data profiling tools to understand and document existing data issues [13].
Using tools to clean up data and fix any problems found makes the way we enter information standards [14].
Using tools to check data quality regularly and having a clear view of it through a dashboard [15].
Post-implementation, the company noticed a big drop in mistakes with information, better keeping to rules reports, and more belief that decisions based on data are right [16].
In the context of the IT industry, the strategies for data quality improvement play a pivotal role in the accuracy and reliability of analytical results. Data profiling and cleansing, along with validation and verification, are fundamental steps to rectify inconsistencies and ensure data integrity. However, these processes can be resource-intensive, particularly for large datasets [17]. It's critical to strike a balance between the effort invested and the potential improvement in data quality. Additionally, while data governance frameworks and metrics provide structure for managing data quality, their effectiveness heavily depends on organizational commitment and enforcement.
Weak governance or poorly defined metrics can lead to a lack of accountability and ineffective data quality management [18]. Data quality tools offer automation, which is advantageous for efficiency, but their cost and complexity may not align with the budgets and needs of smaller IT organizations. Continuous monitoring and real-time anomaly detection are essential for immediate issue identification, but they require infrastructure and ongoing maintenance [19]. Finally, while investing in training and education is vital to building expertise within the team, organizations should carefully assess the long-term benefits against the upfront costs. In conclusion, these strategies are valuable but come with inherent challenges and costs that need to be critically evaluated and tailored to each organization's unique circumstances and objectives [20].
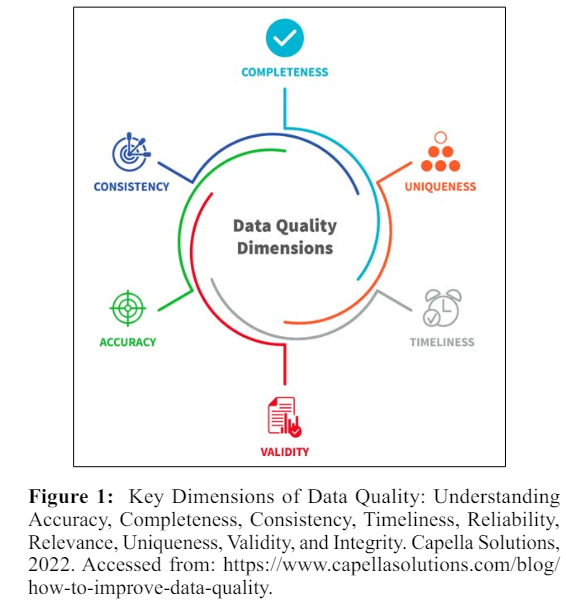
This example illustrates that data quality dimensions are critical criteria for assessing the suitability of data for use, encompassing accuracy, completeness, consistency, timeliness, reliability, relevance, uniqueness, validity, and integrity. Accuracy ensures the data correctly reflects real-world values, while completeness involves having all necessary data present. Consistency requires uniformity in data across various datasets, and timeliness refers to data being up-to-date and available when needed [1].
Reliability denotes the trustworthiness of data, and relevance assesses its applicability to the current task. Uniqueness ensures no duplicates exist, validity checks the data against defined rules and formats, and integrity maintains data's accuracy and consistency throughout its lifecycle. Together, these dimensions provide a comprehensive framework to evaluate and ensure data quality, making it a dependable asset for any organization or business process [4].
Data profiling is a basic task for better data quality. It's about carefully examining the data's content, shape, and quality. This step is very important to find mistakes, strange things, and patterns that must be looked at before any changes or better plans are used. Keeping track of data helps to find problems with things being right, complete, and matching. This is important for making decisions because we must ensure our data is good [5].
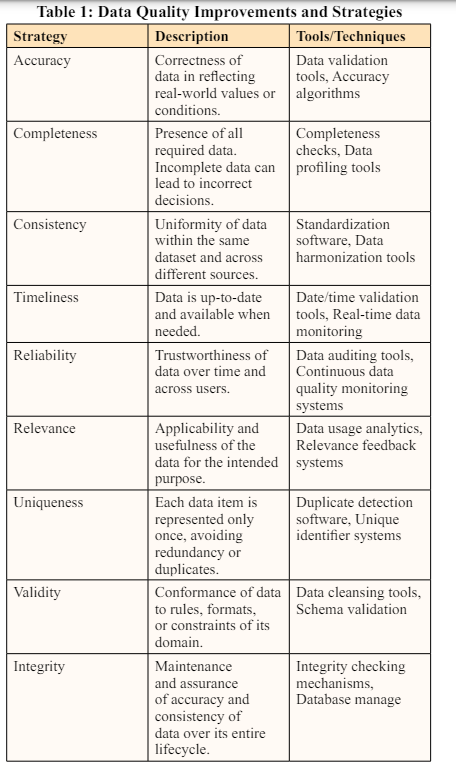
This table succinctly captures the essence of each data quality improvement strategy while providing examples of tools or techniques typically associated with each.
The techniques for data profiling include column profiling, crosscolumn analysis, and data rule validation. Different tools are used to make this easier. Both Informatica Data Quality and IBM Infosphere Information Analyzer are popular choices. Also, it's common to use SAS Data Management. [6]. These give tools to check if data is good, see how it's made, and spot anything unusual. They give a complete picture of how healthy the data is and where things need to be changed.
Fixing or deleting wrong, messed up, wrongly set out, repeated, or uncompleted data within a set of information is key to improving data. This process aims to clean up anything that makes the data wrong so it can be used properly. Methods can be as easy as taking out doubles or fixing spelling errors, to harder ways like math-based steps, spotting strange things that don't fit the pattern normally seen, or machine learning tricks for guessing and fixing mistakes. When people fix mistakes by hand, they check and change data. But when we use computer methods, most of the time, those repairs can be made automatically, which makes things faster and able to be done on a bigger scale. Open Refine, Trifacta, and Talend Data Quality are often used to clean up data. These tools can find and fix mistakes and change data types. This makes the act of cleaning up data faster and better [8].
A strong system for managing data quality is necessary to ensure the data stays good over time. It includes rules, norms, steps, and tools that all work together to keep data quality high over time. This plan usually has rules for managing data, ways to measure quality, assigned tasks and duties, along with ongoing improvements. This plan needs to match up with the company aims and rules, ensuring that work done to improve data is part of the bigger picture and follows all necessary laws. In a team that checks data quality, important jobs are looking after the data (data stewards), checking how good the data is (data quality analysts), and managing the data (data managers). Data stewards make sure that data is correct, easy to get to, the same all over, and filled out. Data quality analysts work on watching, reviewing, and improving the goodness of data. Data managers watch over data and follow the rules and policies set for handling it [9].
Regular checking is a way to keep data good by checking it and ensuring it matches what we know is okay. We also quickly spot new problems when we do this. Continuous monitoring allows organizations to improve the efficiency and effectiveness of their processes. By understanding where they excel and where they fall short, businesses can take action to elevate their performance [10]. This iterative process allows us to set up ways to measure data quality and some goals. Use special displays for monitoring day-to-day data. Also, use automatic tools to spot and warn when something is wrong with the data.
To improve data quality, we need to check and improve our ways of working with data often. This means looking at strategies and ways, we get better details. This job regularly checks data quality, looks at whether different ways to fix data problems work well, and changes plans when new data problems arise, or businesses change what they need. This method ensures that we keep our data good and always change it based on the company's situation and needs [11].
Set clear, measurable goals for improving data quality. These may involve goals for correctness, thoroughness, or speed. Set up ways to track these goals [12].
Check the current data status using techniques like looking at data (data profiling) and reviewing records (auditing). Find ways to get better and write down the problems you face [13].
Figure out what needs to be done, then make a clear plan showing the steps and ways needed to improve data. Add duties, deadlines, and necessary resources [14].
Fix problems found by using data cleaning tools and methods. This might involve algorithmic corrections for large datasets or manual corrections for more complex issues [15].
Implement a data governance framework to ensure ongoing data quality. This should include policies, standards, roles, and responsibilities related to data management and quality [2, 4].
Set up systems for continuous monitoring of data quality using dashboards and alerts. Regularly check and fix how we improve data quality, adjusting for new problems or changes in the organization's needs [16].
Integration of Data Quality Improvement in the Software Development Lifecycle (SDLC) [17].
The early steps of SDLC include the need for good data quality. Know and write down what the final users need and hope for in terms of good data and other interested parties [18].
Make the system with good data in thought; think about how data will be taken down, kept, and looked after. During the building process, implement rules that check and manage mistakes in the information, along with steps to handle these errors [19].
Include data quality testing as part of the overall testing process. Use sample data to test for accuracy, consistency, and other quality dimensions [20].
When deploying new systems or updates, ensure that data quality tools and processes are integrated and that the transition maintains the integrity of the data [1].
During the maintenance phase, continuously monitor data quality and adjust as needed. This includes correcting any new issues and adapting to changes in data use or requirements [2].
By integrating data quality improvement processes into each stage of the SDLC, organizations can ensure that data quality is a continuous focus and that systems are designed and operated to maintain high-quality data.
Role of Machine Learning and AI in Data Quality Improvement The advent of machine learning (ML) and artificial intelligence (AI) has changed how we make data better. These tools give clever ways to find and fix problems with data quality and guess and stop them from happening in the future. Computer learning methods can check large numbers to see shapes, odd things, and changes that people could never find by hand [3]. For example, learning methods with guidance can be taught on a set of data that has known problems with its quality. This helps them to understand and guess these same problems in new sets of information. In the same way, unsupervised learning can spot strange shapes or uncommon things in information that may point to possible problems with its quality [4].
AI, mainly through talking and understanding like humans do (NLP), plus machine sense, makes old data check tools work even better. It does this by getting the data we give it in ways that are much faster and at a big size very fast. This can be very handy for getting the meaning and use of data, which are key parts of how good the data is. AI can take care of hard choices linked to fixing, checking, and making data better automatically. This reduces the need for human help and the chances of people making mistakes [5].
Looking forward, several emerging trends and technologies promise to enhance data quality management further [6]:
More and more, people are looking into blockchain technology to make sure data is correct and from where it should be. Blockchain ensures data history is clear and can't be changed using timestamped records. It lets everyone see the changes made to the data clearly and safely. This is especially helpful in situations that need top-notch safety and checking, like money deals or managing supplies [7].
The ideas of data fabric and data mesh emphasize creating a unified environment for data. They help connect different data sources and types in an easily understandable way. These methods use smart math, computer brains, and ways to combine data. They create one big smart plan for handling data CPR across the company. They can find and fix any problems with data all by themselves [8].
Cloud data quality services are coming up. This is good for firms because they can get automated, growing, and anytime solutions for keeping their data tidy. These services use cloud computing and ML/AI abilities to constantly profile, clean, and add details to data without needing much equipment or knowledge inside the company. They offer it all the time without extra work from us [9].
Boosted data handling uses machine learning (ML) and AI to do many hand jobs in looking after data. This includes fixing up bad data. It lets us act smarter and faster on data mistakes. It learns as time passes, helping to see and stop these mistakes before they happen [10].
Using high-tech tools like ML and AI to keep data clean is very important. As these techs keep changing, they offer cleverer, quicker, and better tools for ensuring that data is quality. Adding things like blockchain and data fabric to future trends will improve how we fix data quality. This includes Data Quality as a Service (DQaaS) and using computers to help manage data. This area is improving every day, and it will help businesses use all their data properly [11].
Making data better comes with problems that can slow things down and mess up the information. Some of the common challenges include [12]:
In many groups, data is spread out across differing machines and ways. This makes it hard to have one place for facts. It's hard to mix this information because systems have different ways of keeping it, the shape it takes, and the skills needed [13].
With a clear leader or rules, data quality projects might know what they want to achieve and who's responsible. Ensuring data stays good always needs clear jobs and duties to be done, but in many companies, these usually need to be clarified or better set [14].
Employees might push back against changes to their job routines, especially if they don't see the good that projects for better data quality can bring. This pushback can hold back or mess up attempts to make data better [15].
As businesses grow, they also make more and save a lot of information. Keeping data quality up can be a hard job as data sources, types, and how it is used change all the time [16].
Best Practices and Solutions to Overcome These Challenges Despite these challenges, there are several best practices and solutions organizations can adopt to enhance their data quality:
Setting up a strong data rules system is very important. This structure should tell what everyone's job is, their duties, and measures for data control. Also, it must describe ways of your actions to improve the quality [17].
Promote a way of thinking where people all over the company know data quality matters and feel responsible for keeping it right. Give workers training and support to help them know how they play a part in keeping data good [18].
Use high-level tools and tech to look at data, fix errors, and watch it carefully. Using machines and learning can ensure data is good, much better, and faster [19].
Data quality is not a one-time project but an ongoing process. Implement continuous monitoring with clear metrics and regular audits. Use the insights gained to continuously refine and improve data quality processes [20].
The Global World Bank had issues with the correctness of its data, which affected how it reported about following rules. The bank implemented a complete way to control its data and set up a single team of people who manage this information. By ensuring data is clean and checking it continuously, the bank got better at keeping their information up-to-date and correct. This helped them follow the rules more easily, lowering the chance of getting fined because they didn't break any laws [16, 18].
A big healthcare company learned that patient information needed to be clearer and included, which hurt the care of patients and how they worked. They started a better data quality program that involved teaching staff, using tools to watch data quality, and having a group from different areas watch over the data. So, the person who provided the service saw much better patient records with fewer mistakes and missing entries. This helped patients do better and made the work process go smoother [19].
Fixing data quality issues is important, but we can do it by planning, using the right tools and power, and always making things better. That's our pledge and promise. Real examples show that groups can beat problems with careful work, making their data much better [20].
In the world of IT, good data is not just something we want but a basic need that helps us do our job well, make important choices, and keep customers happy. The goodness of facts affects how trusty and useful business knowledge, studying data, and all the processes to make a choice work. Groups that have very good data can be sure of getting information that is more correct, always the same, and on time. This leads to better work, being better than others, and following rules set by law. On the other hand, bad information can cause wrong choices, lower customer happiness, and big money losses. It can also harm how people see or think about the group.
This paper has outlined a complete list of methods to improve data, covering different parts of the problem:
Helps understand and diagnose the current state of data quality, identifying areas for improvement.
Focuses on rectifying or eliminating incorrect or inconsistent data, thus enhancing the accuracy and reliability of the data set.
Sets up the rules, levels, and actions required to keep data quality up to date. This involves jobs like data handlers and data quality supervisors.
Being careful with data is not just a one-time action but stays checked and improved to handle new problems and data sources.
The benefits of these strategies are far-reaching, contributing to improved efficiency, decision-making, customer satisfaction, and regulatory compliance. Organizations that effectively implement these strategies can expect a significant return on investment through increased operational efficiencies, better decision-making capabilities, and a strong competitive position in the market.
In the fast-paced and ever-changing world of computers, maintaining good data is a goal that keeps changing. It needs constant care and effort. When new tools come up, and the amount of information keeps getting bigger, it will only get harder to keep a high standard for data quality. However, having good data quality can lead to better choices, smooth work, happy customers, and being ahead of others. This makes it worth the cost. Organizations, businesses, and companies should think about data quality as a trip that never ends and one where everyone in the company has to be included.
By creating a way of working that sees data as important, always putting money into the best tools and tech, and changing plans to meet new problems, groups can be sure their facts stay useful and true to help businesses succeed. Ultimately, the promise to have good data is an important plan for any group that wants to do well in the digital time. By knowing how important good data is, putting into action the ideas discussed, and staying with a promise to keep improving, businesses can use their info at their best. This will push new ideas forward, make work faster and smoother, and help them grow.