DataOps: Bridging the Gap Between Legacy and Modern Systems for Seamless Data Orchestration
Author(s): Ramakrishna Manchana
Abstract
The modern enterprise operates in a complex data landscape, where legacy systems coexist with modern, event-driven microservices architectures. This heterogeneity poses significant challenges in data integration, management, and analysis. DataOps, a methodology that applies DevOps principles to the data lifecycle, offers a solution to these challenges. This paper explores the implementation of DataOps in such a hybrid environment, focusing on strategies for integrating and orchestrating data from diverse sources, ensuring data quality, and enabling efficient data-driven decision-making. The paper also highlights the crucial role of Data Lakes and Data Lake houses in facilitating seamless data orchestration, providing a scalable and flexible foundation for storing, processing, and analyzing data from both legacy and modern systems.
Introduction
The contemporary enterprise is characterized by a diverse and ever-evolving data landscape. Legacy systems, often monolithic and built on outdated technologies, continue to play a crucial role in many organizations. At the same time, modern, cloud-native technologies, such as microservices and event-driven architectures, are increasingly adopted to enable agility, scalability, and real-time data processing. This coexistence of legacy and modern systems creates a hybrid environment that poses significant challenges for data management and analysis.
DataOps, inspired by the principles of DevOps, offers a collaborative and process-oriented approach to address these challenges. By emphasizing automation, continuous integration, and delivery (CI/CD), and monitoring, DataOps streamlines the entire data lifecycle, from ingestion to consumption. It fosters collaboration between data engineers, data scientists, and other stakeholders, breaking down silos and promoting shared ownership of data processes.
This paper delves into the implementation of DataOps in a hybrid environment, exploring strategies for integrating and orchestrating data from legacy and modern systems. It also discusses the importance of data quality, governance, and visualization in enabling effective data-driven decision-making. The paper further highlights the pivotal role of Data Lakes and Data Lakehouses in facilitating seamless data orchestration, providing a scalable and flexible foundation for storing, processing, and analyzing data from both legacy and modern systems.
Literature Review
The literature on DataOps is rapidly expanding, reflecting its growing importance in the data management landscape. Early works by authors like Lenley Hensarling (2014) and Andy Palmer (2015) laid the groundwork by introducing the concept and emphasizing the need for collaboration and automation in data workflows. The term "DataOps" itself was coined around 2015, and since then, numerous publications and conferences have explored its principles, practices, and benefits.
The literature on DataOps encompasses a wide range of topics, including
- Principles and Practices: The core principles of DataOps, such as collaboration, automation, continuous integration, and delivery (CI/CD), and monitoring, are extensively discussed in the literature. Various publications offer practical guidance on implementing these principles, including best practices for data pipeline development, testing, deployment, and
- Benefits and Challenges: The literature highlights the potential benefits of DataOps, such as improved data quality, faster time to insights, increased operational efficiency, and enhanced collaboration between data teams. However, it also acknowledges the challenges associated with DataOps adoption, including cultural shifts, skill gaps, and the need for appropriate tools and technologies.
- ToolsandTechnologies: The DataOps ecosystem is rapidly evolving, with a growing number of tools and platforms designed to support DataOps practices. The literature explores various tools for data integration, orchestration, quality, governance, visualization, and monitoring, providing insights into their capabilities and suitability for different use
- Case Studies and Success Stories: Numerous case studies and success stories showcase the real-world impact of DataOps across various These examples demonstrate how organizations have leveraged DataOps to improve their data operations, accelerate innovation, and achieve business objectives.
- FutureTrends: The literature also explores emerging trends in DataOps, such as the integration of machine learning and artificial intelligence (AI) for intelligent data operations, the adoption of cloud-native technologies for scalability and flexibility, and the increasing focus on data security and Overall, the literature on DataOps provides a rich and valuable resource for understanding the principles, practices, benefits, and challenges associated with this methodology. It offers practical guidance for organizations seeking to implement DataOps and leverage its potential to transform their data operations and drive business value.
The DataOps Paradigm
DataOps, at its core, is a methodology that borrows from DevOps principles and applies them to the data lifecycle. It advocates for collaboration, automation, and continuous improvement to bridge the gap between data engineers, data scientists, and other stakeholders. In the context of modern and legacy system integration, DataOps plays a pivotal role in:
- Data Orchestration: DataOps provides the tools and processes to orchestrate the flow of data from diverse sources, including event streams, databases, and file systems. This ensures that data is ingested, transformed, and delivered to the right destinations in a timely
- Data Quality and Governance: DataOps emphasizes data quality checks and governance mechanisms to maintain the integrity and reliability of data throughout its This is especially critical when dealing with legacy systems that may have inconsistencies or outdated data formats.
- Scalability and Agility: DataOps frameworks enable organizations to scale their data operations as data volumes grow and business requirements The ability to quickly adapt to new data sources and technologies is crucial in a dynamic environment.
- Collaboration and Communication: DataOps fosters a culture of collaboration between data teams, breaking down silos and promoting shared ownership of data processes. This is essential for effective troubleshooting, optimization, and innovation.
Components
The core components of Data Ops include
- Data Pipelines: The series of steps involved in extracting, transforming, and loading (ETL) data from various sources to target destinations.
- Data Orchestration: The coordination and management of data pipelines, ensuring their efficient and reliable execution.
- Data Quality: The processes and tools used to ensure the accuracy, completeness, and consistency of
- Data Governance: The policies, procedures, and standards that define how data is managed and used within an
- Data Visualization and Analytics: The tools and techniques used to explore, analyze, and present data in a meaningful
- Monitoring and Observability: The collection and analysis of metrics and logs to gain insights into the health and performance of the DataOps
Challenges in Integrating with Legacy and Modern Systems The coexistence of legacy and modern systems within the same enterprise data ecosystem presents a unique set of challenges that can impede the seamless flow and utilization of data. These challenges stem from the inherent differences in architecture, data formats, processing capabilities, and technological maturity between these two types of systems.
- Data Format Incompatibility: Legacy systems, often developed decades ago, may rely on proprietary or outdated data formats that are not readily compatible with modern data processing tools and This incompatibility can create significant hurdles in data integration and transformation efforts, requiring additional steps and resources to bridge the gap between the old and the new.
- Real-Time Batch Processing: Modern systems, particularly those built on cloud-native architectures, are often designed to handle real-time or near-real-time data processing, enabling rapid response to events and changes in the data landscape. Legacy systems, on the other hand, may be optimized for batch processing, where data is collected and processed in large chunks at scheduled intervals. This discrepancy in processing capabilities can lead to synchronization issues and delays in data availability, hindering the ability to derive timely insights.
- Data Latency and Consistency: The movement of data between systems with different architectures and processing speeds can introduce latency, or delays in data availability. Moreover, ensuring data consistency across these disparate systems can be challenging, as updates and changes made in one system may not be immediately reflected in This can lead to inconsistencies and inaccuracies in data analysis and decision-making.
- Technical Debt: Legacy systems often carry a burden of technical debt, accumulated over years of modifications and This technical debt can manifest in the form of outdated technologies, poor documentation, and lack of support, making it difficult to integrate these systems with modern data pipelines and tools. The effort and resources required to overcome this technical debt can be substantial, impacting the overall efficiency and agility of data operations.
Integration Approaches with Legacy and Modern Systems Integrating legacy and modern systems requires a nuanced approach that considers the unique characteristics and constraints of each system type. Some common integration approaches include:
Legacy Systems (Monolithic, etc.)
- Change Data Capture (CDC): This technique captures changes made to data in legacy systems and propagates them to modern systems in real-time or near-real-time. This allows for incremental updates and synchronization between the two environments.
- API Wrappers: Wrapping legacy system interfaces with APIs can provide a modern and standardized way to access data and functionality from these systems. This enables easier integration with modern tools and platforms.
- Message Queues: Message queues can be used to facilitate asynchronous communication between legacy and modern This can be particularly useful when dealing with systems that have different processing speeds or data formats.
Modern Systems (Event-Driven Microservices, etc.)
- Event-DrivenIntegration: Modern systems built on event- driven architectures can publish events to notify other systems of changes or DataOps pipelines can consume these events to trigger actions or workflows, enabling real-time or near-real-time data processing.
- MicroservicesIntegration: Microservices, with their loose coupling and independent deployment, can be integrated with DataOps pipelines using APIs or message queues. This allows for flexible and scalable data orchestration.
- Cloud-Native Integration: Cloud-native technologies, such as serverless functions and managed services, can be leveraged to build and deploy DataOps pipelines in a scalable and cost-effective manner.
Integration with Arcghitecture Layers
DataOps can be integrated with various architecture layers to enable seamless data flow and analysis:
- UI to API: User interactions in the UI can trigger events that are sent to APIs for processing. DataOps pipelines can consume these events to update data stores or trigger other
- API to API: APIs can communicate with each other asynchronously through events or message queues. DataOps can orchestrate the flow of data between these APIs, ensuring data consistency and integrity.
- APItoMiddleware/BackendServices: Events can be used to trigger workflows and orchestrate business processes in middleware or backend systems. DataOps can monitor and manage these workflows, ensuring their efficient
- DataPipelinesand ETL Processes: DataOps pipelines can be triggered by events or scheduled jobs to extract, transform, and load data from various sources.
- Other Layers: DataOps can also be integrated with other architecture layers, such as messaging and notification systems, monitoring and logging, security systems, and IoT and edge computing, to enable data-driven insights and
Datalake and Datalakehouse in DataOps
The Role of Data Lakes and Data Lakehouses in DataOps In the context of DataOps, Data Lakes and Data Lakehouses play a crucial role in facilitating seamless data orchestration and management across diverse systems.
- Data Lakes as Centralized Repositories: Data Lakes serve as centralized repositories for storing vast amounts of raw data in its native They can accommodate structured, semi-structured, and unstructured data from various sources, including legacy systems, modern applications, and real-time data streams. In a DataOps environment, Data Lakes act as a landing zone for incoming data, providing a flexible and scalable storage solution.
- Data Lakehouses for Advanced Analytics: Data Lakehouses combine the scalability and cost-effectiveness of Data Lakes with the data management and ACID (Atomicity, Consistency, Isolation, Durability) transaction capabilities of data warehouses. This enables organizations to perform advanced analytics, such as machine learning and real-time reporting, directly on the data stored in the lake, eliminating the need for complex data movement and transformation
Key Benefits of Data Lakes and Data Lakehouses in DataOps
- Data Democratization: By centralizing data storage and providing easy access to diverse datasets, Data Lakes and Data Lakehouses promote data democratization, empowering various teams and individuals within the organization to explore and analyze data independently.
- Self-Service Analytics: Data Lakes and Data Lakehouses enable self-service analytics, allowing users to access and analyze data without relying heavily on IT or data engineering This accelerates the time to insights and fosters a culture of data-driven decision-making.
- Collaboration and Agility: These technologies facilitate collaboration between different teams by providing a shared platform for data access and analysis. They also enable greater agility in responding to changing business requirements, as new data sources and use cases can be easily accommodated within the lake or lake house environment.
Integrating Data Lakes and Data Lakehouses into DataOps
- Data Ingestion: DataOps pipelines can efficiently ingest data from various sources into the Data Lake or Data Lakehouse, leveraging their scalability and flexibility to handle large volumes and diverse formats of data.
- Data Transformation and Enrichment: DataOps pipelines can perform data transformation and enrichment tasks within the Data Lake or Data Lakehouse, cleaning, standardizing, and enriching the raw data to make it suitable for analysis.
- Data Access and Consumption: DataOps can facilitate access to the processed data in the Data Lake or Data Lakehouse for various downstream applications and users, such as data scientists, business analysts, and reporting
- Metadata Management: Data Lakes and Data Lakehouses can leverage metadata management tools to track data lineage, definitions, and relationships, enabling better data discovery, governance, and compliance.
- Data Security and Governance: DataOps can implement security and governance policies within the Data Lake or Data Lakehouse to protect sensitive data and ensure compliance with regulatory requirements.
By incorporating Data Lakes and Data Lakehouses into their DataOps strategy, organizations can create a unified and scalable data platform that supports a wide range of use cases, from traditional reporting to advanced analytics and machine learning. This enables them to derive valuable insights from their data, make informed decisions, and drive innovation in today's competitive landscape.
Industry Use Cases
The adoption of DataOps has transcended various industries, revolutionizing how businesses manage and leverage their data assets. The following use cases illustrate the transformative impact of DataOps across different sectors:
- Healthcare: The healthcare industry deals with vast amounts of sensitive patient data, requiring stringent data governance and security measures. DataOps enables healthcare organizations to streamline data pipelines, ensuring the timely and accurate delivery of patient information to clinicians and This facilitates improved patient care, faster diagnosis, and more effective treatment plans. Additionally, DataOps can support population health management initiatives by enabling the analysis of large datasets to identify trends and patterns that can inform public health interventions.
- Finance: The financial sector relies heavily on data for risk management, fraud detection, and algorithmic trading. DataOps can help financial institutions to integrate and analyze data from diverse sources, such as market feeds, customer transactions, and regulatory filings. This enables them to make more informed investment decisions, identify potential risks, and detect fraudulent activities in real-time.
- Retail: The retail industry is increasingly leveraging data to understand customer behavior, personalize marketing campaigns, and optimize inventory management. DataOps can help retailers to integrate data from various touchpoints, such as online stores, mobile apps, and physical This enables them to gain a 360-degree view of their customers, deliver targeted promotions, and ensure that products are available when and where customers need them.
- Manufacturing: The manufacturing sector is undergoing a digital transformation, with the adoption of technologies such as the Internet of Things (IoT) and predictive DataOps can help manufacturers to collect and analyze data from sensors, machines, and other sources on the factory floor. This enables them to optimize production processes, predict equipment failures, and improve product quality.
- Energy: The energy industry is facing challenges such as the integration of renewable energy sources, the modernization of the grid, and the need for demand DataOps can help energy companies to collect and analyze data from smart meters, sensors, and other sources. This enables them to optimize energy production and distribution, predict demand, and respond to fluctuations in supply and demand.
These use cases demonstrate the versatility and adaptability of DataOps across different industries. By enabling organizations to effectively manage and leverage their data assets, DataOps can drive innovation, improve operational efficiency, and enhance customer experiences.
Industry Case Studies
Retail Estate DataOps Transformation with Aws
A major retail company faced the challenge of integrating data from disparate systems, including legacy inventory management systems and modern e-commerce platforms. The company aimed to leverage this data to gain real-time insights into inventory levels, optimize stock allocation, and enhance the overall customer experience.
The Challenge
The legacy inventory management systems, often based on outdated technologies and batch-oriented processing, struggled to keep up with the demands of real-time inventory tracking and omnichannel fulfillment. The modern e-commerce platforms, on the other hand, generated a continuous stream of events related to customer orders, product views, and cart additions. The company needed a way to bridge the gap between these systems and enable seamless data orchestration and analysis to support real-time inventory visibility and decision-making.
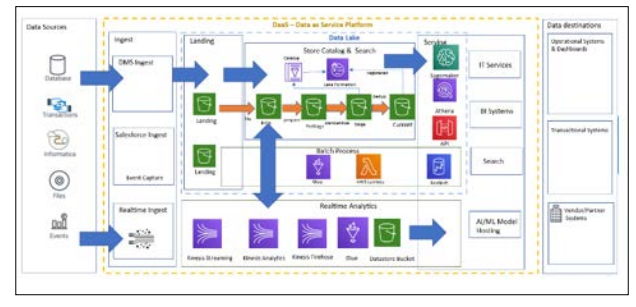
The DataOps Solution Leveraging AWS
The company adopted a DataOps approach to address this challenge, leveraging Amazon S3 as a centralized Data Lake for storing and processing data from both legacy and modern systems. The following DataOps components, implemented using AWS services, played a crucial role in the solution:
Data Pipelines
- LegacySystems: AWS Database Migration Service (DMS) was used to extract data from legacy inventory management systems, replicating changes in near-real-time to the Data This ensured that the Data Lake always had the most up-to-date inventory information.
- Modern Systems: Amazon Kinesis Data Streams was employed to capture the high-volume, real-time events generated by the e-commerce platforms. Amazon Kinesis Data Firehose or Kinesis Data Analytics was then used to process and transform the event data before delivering it to the Data
Data Orchestration: AWS Step Functions orchestrated the complex workflows involved in data ingestion, transformation, and loading. It coordinated the execution of various AWS Glue jobs, Lambda functions, and other services, ensuring the reliability and efficiency of the data pipelines.
Data Quality: Data quality checks were incorporated into the pipelines using AWS Glue or custom scripts to ensure the accuracy, completeness, and consistency of the data ingested into the Data Lake. This included data profiling, validation, and cleansing processes to identify and rectify any data anomalies or inconsistencies.
Data Governance: AWS Lake Formation was implemented to establish and enforce data governance policies and procedures, defining data ownership, access controls, and usage guidelines. This ensured that data was used responsibly and in compliance with regulatory requirements.
Data Visualization and Analytics: The company leveraged Amazon Athena and Amazon Redshift to query and analyze the data stored in the Data Lake. These services provided powerful SQL-based querying capabilities, enabling the company to generate reports, dashboards, and visualizations to gain insights into inventory levels, sales trends, and customer behavior.
Monitoring and Alerting: Amazon CloudWatch was used to monitor the health and performance of the DataOps system, including the data pipelines, Data Lake, and analytics services. It collected logs and metrics from various components, providing real-time visibility into the data flow and enabling proactive identification and resolution of any issues or bottlenecks.
The Outcome
The implementation of DataOps, coupled with the use of Amazon S3 as a Data Lake, enabled the retail company to successfully bridge the gap between its legacy and modern systems. The company was able to:
- Achieve Real-Time Inventory Visibility: By integrating data from legacy and modern systems into the Data Lake and processing it in near-real-time, the company gained up-to- the-minute insights into inventory levels across all
- Optimize Stock Allocation: The ability to analyze inventory data in real-time allowed the company to optimize stock allocation across different stores and warehouses, reducing stockouts and overstocks.
- Enhance the Customer Experience: Real-time inventory visibility enabled the company to provide accurate product availability information to customers, improving their shopping experience and increasing sales.
- Foster Collaboration: DataOps fostered collaboration between different teams within the organization, breaking down silos and promoting a data-driven culture.
Conclusion
This case study demonstrates the power of DataOps in enabling seamless data orchestration and analysis in a hybrid retail environment, specifically utilizing the AWS stack. By leveraging Amazon S3 as a Data Lake and adopting DataOps best practices, organizations can overcome the challenges of integrating legacy and modern systems, unlock the full potential of their data assets, and drive innovation in today's data-driven world.
Real Estate DataOps Transformation with Azure
A prominent real estate company faced the challenge of integrating data from two disparate systems: a legacy monolithic architecture for Lease Abstraction and a modern, event-driven microservices architecture for Facility Management. The company sought to leverage the data from both systems to gain a comprehensive understanding of its operations, optimize resource allocation, and improve decision-making.
The Challenge
The legacy Lease Abstraction system, while containing valuable historical lease data, was difficult to integrate with modern analytics tools due to its outdated data formats and batch-oriented processing. The modern Facility Management system, on the other hand, generated a continuous stream of real-time events related to building operations, maintenance, and energy consumption. The company needed a way to bridge the gap between these two systems and enable seamless data orchestration and analysis.
The DataOps Solution Leveraging Azure
The company adopted a DataOps approach to address this challenge, leveraging Azure Data Lake Storage Gen2 as a centralized repository for storing and processing data from both legacy and modern systems. The following DataOps components, implemented using Azure services, played a crucial role in the solution:
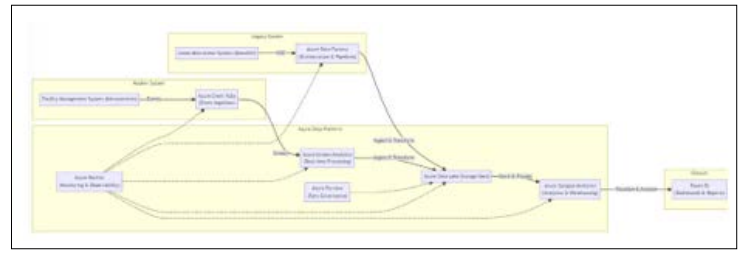
Data Pipelines
- Legacy System (Lease Abstraction): Azure Data Factory pipelines were established to extract data from the legacy Lease Abstraction system using Change Data Capture (CDC). The pipelines were configured to monitor the database transaction logs for changes, capture those changes in near- real-time, and transform the data into a compatible format, such as Parquet or Avro, before loading it into the Data Lake. This ensured that the Data Lake always had the most up-to- date lease information.
- Modern System (Facility Management): Azure Event Hubs was employed to capture the high-volume, real-time events generated by the Facility Management system. Azure Stream Analytics, with its ability to process streaming data in real- time, was then used to filter, aggregate, and transform the event data before storing it in the Data Lake. This enabled the company to gain immediate insights into building operations and respond to events
Data Orchestration: Azure Data Factory served as the orchestration tool to manage and coordinate the execution of these data pipelines, ensuring their reliability and efficiency. It handled data dependencies, scheduling, and error handling, providing a centralized control plane for data operations. The visual interface of Data Factory simplified the design and management of complex data workflows, enabling the real estate company to easily monitor and manage the flow of data from both legacy and modern systems into the Data Lake.
Data Quality: Azure Data Quality Services was integrated into the Data Factory pipelines to ensure the accuracy, completeness, and consistency of the data ingested into the Data Lake. It performed data profiling to understand the characteristics of the data, applied data quality rules to identify and flag any anomalies or inconsistencies, and provided data cleansing capabilities to rectify the issues. This ensured that the data in the Data Lake was reliable and trustworthy for further analysis.
Data Governance: Azure Purview was implemented to establish and enforce data governance policies and procedures, defining data ownership, access controls, and usage guidelines. It provided a comprehensive view of the data landscape, enabling data discovery, classification, lineage tracking, and sensitive data management. This ensured that data was used responsibly and in compliance with regulatory requirements, fostering trust and transparency in data usage.
Data Visualization and Analytics: The company leveraged Azure Synapse Analytics to explore and analyze the data stored in the Data Lake. Synapse Analytics, with its ability to handle both structured and unstructured data, provided a unified platform for data warehousing and big data analytics. The company used Synapse's built-in visualization capabilities or integrated it with Power BI to create interactive dashboards and reports, providing insights into lease performance, facility utilization, energy consumption patterns, and other key metrics.
Monitoring and Observability: Azure Monitor was used to track the health and performance of the entire DataOps system, including the data pipelines, Data Lake, and analytics services. It collected logs and metrics from various components, providing real-time visibility into the data flow and enabling proactive identification and resolution of any issues or bottlenecks.
The Outcome
The implementation of DataOps, coupled with the use of Azure Data Lake Storage and related services, enabled the real estate company to successfully bridge the gap between its legacy and modern systems. The company was able to:
- Gain a Unified View of its Operations: By integrating data from both Lease Abstraction and Facility Management systems into the Data Lake, the company gained a comprehensive and holistic understanding of its operations, enabling better decision-making and resource allocation.
- Optimize Lease Management: Insights from lease data, now readily available in the Data Lake, helped the company identify opportunities for renegotiation, optimize rental rates, and improve tenant satisfaction.
- Improve Facility Management: Real-time data from the Facility Management system, ingested into the Data Lake via Event Hubs and Stream Analytics, enabled the company to proactively address maintenance issues, optimize energy consumption, and improve the overall efficiency of its
- Foster Collaboration: DataOps fostered collaboration between different teams within the organization, breaking down silos and promoting a data-driven The centralized Data Lake and the use of collaborative analytics tools like Synapse Analytics enabled seamless data sharing and analysis across teams.
Conclusion
This case study showcases the power of DataOps in enabling seamless data orchestration and analysis in a hybrid environment, specifically utilizing the Azure stack. By leveraging Azure Data Lake Storage and adopting DataOps best practices, organizations can overcome the challenges of integrating legacy and modern systems, unlock the full potential of their data assets, and drive innovation in today's data-driven world.
Leading Electric Vehicle Manufacturer’s DataOps Driven Fleet Management and Charging Optimization
Business Context
The leading electric vehicle manufacturer utilizes a sophisticated SaaS platform hosted on the secure and scalable AWS Cloud to empower its customers with real-time monitoring and management of their electric vehicle fleet and associated charging systems. The platform offers a suite of essential features, including Fleet Management, Vehicle and Charger Monitoring, Key Performance Indicators (KPIs), Dashboards, and Metrics for data-driven decision-making, Smart Charging capabilities, Vehicle to Grid (V2G) operations, Charging Operations, Reporting and Alerts, Device on Demand Logging, and Service Tools. The Engineering Operations team oversees various essential services for a range of devices, including buses, chargers, and multi-dispensers. These services include Device Onboarding, Device Remote Troubleshooting, Device Security Management, Device Firmware Management, and Device Operationalization.
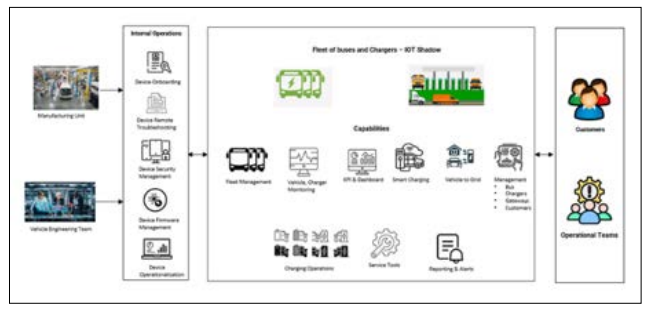
The Challenge
The manufacturer faced the challenge of integrating and orchestrating data from a variety of sources:
- Vehicle Data: Real-time telemetry data from electric vehicles, including location, battery status, and performance metrics, streamed through AWS
- ChargerData: Charging session data, energy consumption, and charger status information collected from OCPP- compliant
- BatteryData: Detailed battery health and performance data transmitted from vehicles via AWS IoT.
- The company needed a robust and scalable solution to ingest, process, and analyze this diverse data to enable real-time monitoring, proactive maintenance, and data-driven decision- making for both the manufacturer and its customers.
The DataOps Solution on AWS
The manufacturer adopted a DataOps approach to address this challenge, leveraging AWS services to build a comprehensive data platform. The following components played a key role in the solution:

Data Ingestion:
- Vehicle and Battery Data: AWS IoT Core was used to securely ingest real-time telemetry and battery data from the electric vehicles.
- ChargerData: OCPP servers collected charger data, which was then ingested into the AWS ecosystem using custom integrations or third-party connectors and stored in Amazon OpenSearch
Data Lake: Amazon S3 served as the central Data Lake, providing a scalable and cost-effective storage solution for all ingested vehicle and battery data.
Data Processing and Transformation
- AWS Lambda: Serverless functions were employed for lightweight data processing and transformation tasks on data stored in S3, offering flexibility and
- Dockerized Spring Boot Application on EKS: A containerized Spring Boot application running on Amazon Elastic Kubernetes Service (EKS) was used for more complex data transformation and enrichment tasks, providing a robust and scalable processing environment.
Data Orchestration: A dockerized Spring Boot application on EKS orchestrated the complex data workflows, coordinating the execution of Lambda functions, the Spring Boot application itself, and interactions with OpenSearch, ensuring efficient and reliable data processing.
Data Storage and Analytics
- Amazon OpenSearch Service: This managed service was used to store and analyze both real-time operational data from chargers and processed data from the Data Lake, enabling quick access to critical information for monitoring, alerts, and complex analytics.
- DockerizedSpringBootApplicationon EKS: The Spring Boot application also interacted with OpenSearch to perform additional data analysis and processing tasks, leveraging its capabilities for advanced analytics and reporting.
Data Visualization: OpenSearch Dashboards was used to create interactive dashboards and visualizations, providing the manufacturer and its customers with real-time visibility into fleet performance, charging infrastructure utilization, and battery health.
Monitoring and Alerting: Amazon CloudWatch was employed to monitor the health and performance of the entire DataOps system, collecting logs and metrics from various components and triggering alerts in case of anomalies or issues.
The Outcome
The implementation of DataOps on AWS enabled the manufacturer to achieve the following outcomes:
- Real-Time Fleet Monitoring: The company and its customers gained real-time visibility into the location, status, and performance of their electric vehicle fleets, enabling proactive decision-making and efficient resource
- Proactive Maintenance: By analyzing real-time vehicle and battery data, the manufacturer could identify potential issues and schedule maintenance proactively, minimizing downtime and reducing maintenance costs.
- Optimized Charging: Insights into charger utilization and energy consumption patterns allowed for optimizing charging schedules and infrastructure planning, improving operational efficiency and reducing energy
- Data-Driven Decision Making: The ability to analyze and visualize data from various sources empowered the manufacturer and its customers to make informed decisions regarding fleet management, charging infrastructure, and overall operations.
Conclusion
This case study demonstrates how a leading electric vehicle manufacturer leveraged DataOps on AWS to overcome the challenges of integrating and orchestrating data from diverse sources. By implementing a robust data platform and adopting DataOps best practices, the manufacturer achieved real-time visibility into its operations, optimized resource allocation, and improved decision-making, ultimately enhancing the value it provides to its customers and driving innovation in the electric vehicle industry.
Implementation Considerations
The successful implementation of DataOps requires careful consideration of several key factors that can significantly impact its effectiveness and adoption within an organization.
- Technology Choices: The selection of appropriate tools and platforms for data integration, orchestration, quality, governance, visualization, and monitoring is crucial. The chosen technologies should align with the organization's specific needs, data volumes, and technological landscape. Factors such as scalability, performance, ease of use, and integration capabilities should be carefully evaluated when making these selections.
- Data Architecture: Designing a robust and adaptable data architecture is fundamental to DataOps success. The architecture should accommodate both legacy and modern systems, enabling seamless data flow and integration. It should also be scalable to handle growing data volumes and flexible enough to adapt to changing business The incorporation of Data Lakes and Data Lakehouses into the data architecture can provide a centralized and scalable repository for storing and processing data from diverse sources, further enhancing the effectiveness of DataOps.
- Process and Collaboration: Establishing clear processes and fostering collaboration between data engineers, data scientists, and other stakeholders is essential for effective DataOps implementation. This includes defining roles and responsibilities, establishing communication channels, and promoting a culture of shared ownership and The use of agile methodologies and DevOps practices can help streamline workflows and facilitate collaboration.
- Skill Development: Investing in the training and development of data teams is crucial for successful DataOps adoption. This involves providing opportunities for team members to upskill in DataOps methodologies, modern data technologies, and legacy system integration techniques. By fostering a culture of continuous learning and development, organizations can empower their data teams to effectively navigate the complexities of the data landscape and drive innovation.
Challenges and Limitations
While DataOps offers numerous benefits, it's important to acknowledge and address its potential challenges and limitations:
- Cultural Shift: Adopting DataOps often requires a cultural shift within an organization, moving away from traditional siloed approaches to data management towards a more collaborative and agile mindset. This can be a significant challenge, requiring strong leadership and change management
- Skill Gaps: DataOps demands a diverse skill set, encompassing data engineering, data science, DevOps, and domain Organizations may face challenges in finding or developing talent with the necessary skills to implement and manage DataOps effectively.
- Tooling and Technology: The DataOps ecosystem is rapidly evolving, with a plethora of tools and platforms available. Selecting the right tools that integrate well with existing systems and support the organization's specific needs can be a daunting task.
- Complexity: Managing data pipelines, ensuring data quality, and maintaining data governance can be complex, especially in a hybrid environment with both legacy and modern DataOps requires careful planning, coordination, and monitoring to avoid bottlenecks, errors, and inconsistencies.
- Cost: Implementing DataOps may require an initial investment in tools, technologies, and training. Organizations need to carefully evaluate the costs and benefits to ensure a positive return on investment.
Best Practices
To maximize the benefits of DataOps and mitigate its challenges, several best practices should be followed:
- Establish Clear Goals and Metrics: Define clear objectives for DataOps implementation and establish measurable metrics to track progress and This ensures that the DataOps initiative is aligned with the organization's overall business goals and provides a way to measure its impact.
- Foster Collaboration: Break down silos between data teams and promote a culture of shared ownership and accountability. Encourage communication and collaboration between data engineers, data scientists, business analysts, and other stakeholders to ensure that everyone is working towards the same
- Automate Wherever Possible: Automate repetitive tasks, such as data ingestion, transformation, testing, and deployment, to improve efficiency and reduce errors. Automation frees up valuable time for data teams to focus on more strategic and value-added activities.
- Implement CI/CD: Apply CI/CD principles to data pipelines, enabling rapid and reliable deployment of changes while ensuring data quality. This allows for faster iteration and experimentation, leading to quicker innovation and improved time to market.
- Monitor and Observe: Implement comprehensive monitoring and observability tools to gain insights into data flows, identify bottlenecks, and proactively address issues. This helps ensure the health and performance of the DataOps system and enables quick troubleshooting and resolution of
- Ensure Data Quality and Governance: Establish data quality checks and governance mechanisms to maintain the integrity and reliability of data throughout its This includes data profiling, validation, cleansing, and lineage tracking to ensure that data is accurate, complete, and compliant with regulatory requirements.
- Invest in Skill Development: Provide training and development opportunities for data teams to upskill in DataOps methodologies and tools. This empowers team members to effectively contribute to the DataOps initiative and stay abreast of the latest technologies and best
- Choose the Right Tools: Select tools and platforms that align with the organization's specific needs, data volumes, and technological landscape. The tools should be scalable, performant, easy to use, and integrate well with existing
- Start Small and Iterate: Begin with a pilot project to test DataOps practices and gradually expand adoption across the This allows for learning and refinement of processes before full-scale implementation, reducing risks and ensuring a smoother transition.
- By adhering to these best practices, organizations can increase the likelihood of successful DataOps implementation, enabling them to derive greater value from their data assets and achieve their business objectives.
Opportunity Cost Analysis of DataOps
The adoption of DataOps, while promising significant benefits, also entails certain opportunity costs that organizations must carefully consider. The primary costs associated with DataOps implementation include:
- Initial Investment: The implementation of DataOps necessitates an initial investment in tools, technologies, and The acquisition of specialized DataOps platforms, data integration tools, data quality management solutions, and other relevant technologies can incur substantial costs. Additionally, organizations need to invest in training their data teams on DataOps methodologies, tools, and best practices, which can further add to the initial expenditure.
- Learning Curve: The adoption of DataOps often requires a cultural shift and a learning curve for teams accustomed to traditional data management practices. The transition to a more collaborative, automated, and agile approach may initially lead to a temporary dip in productivity as teams familiarize themselves with new tools, processes, and ways of working.
- Complexity: Managing a hybrid environment with both legacy and modern systems can add complexity to DataOps The integration and orchestration of data flows across disparate systems, with varying data formats, processing capabilities, and technological maturity, can be intricate and demanding. This complexity may necessitate additional effort, expertise, and resources to ensure seamless data operations.
- Potential Risks: The implementation of DataOps involves changes to data pipelines, processes, and technologies, which can introduce potential risks such as data inconsistencies, errors, and downtime. Organizations need to carefully plan and execute their DataOps initiatives, incorporating robust testing and validation procedures to mitigate these risks and ensure the integrity and reliability of their data.
However, the potential benefits of DataOps, such as improved data quality, faster time to insights, increased operational efficiency, and enhanced collaboration, often outweigh the costs. By enabling organizations to make more informed and timely decisions based on reliable data, DataOps can drive innovation, improve customer experiences, and ultimately lead to a competitive advantage. The opportunity cost of not adopting DataOps lies in the potential missed opportunities for growth, efficiency gains, and competitive differentiation that can be achieved through effective data management and utilization.
Therefore, organizations need to carefully weigh the potential costs and benefits of DataOps implementation, considering their specific needs, resources, and strategic objectives. By adopting a thoughtful and well-planned approach, organizations can successfully navigate the challenges and reap the rewards of DataOps, unlocking the full potential of their data assets and driving business value in the data-driven era.
Future Trends
The field of DataOps is rapidly evolving, with several emerging trends shaping its future:
AI and ML Integration: The integration of artificial intelligence (AI) and machine learning (ML) into DataOps processes is gaining traction. AI and ML can be leveraged to automate various aspects of data operations, including:
- DataQuality: AI/ML models can be trained to identify and rectify data quality issues, such as inconsistencies, errors, and missing values, in real-time or near-real-time. This can significantly improve the accuracy and reliability of data, leading to better decision-making.
- Anomaly Detection: AI/ML algorithms can be employed to detect anomalies or outliers in data patterns, which may indicate potential problems or opportunities. This can help organizations proactively address issues and identify new
- PipelineOptimization: AI/ML can be used to analyze data pipeline performance and suggest optimizations, such as resource allocation, task scheduling, and data partitioning, to improve efficiency and reduce costs.
Cloud-Native DataOps: As organizations increasingly adopt cloud-native architectures, DataOps is also moving to the cloud. Cloud-native DataOps platforms offer several benefits, including:
- Scalabilityand Elasticity: The ability to scale resources up or down based on demand, ensuring optimal performance and cost-efficiency.
- Flexibilityand Agility: The ability to quickly provision and de-provision resources, enabling rapid experimentation and deployment of new data pipelines and
- Managed Services: The availability of managed services for various DataOps components, such as data integration, orchestration, and quality, reducing the operational overhead for
Data Security and Privacy: With the growing importance of data protection and privacy regulations, DataOps is placing a greater emphasis on security. This includes:
- Robust Access Controls: Implementing fine-grained access controls to ensure that only authorized users can access sensitive
- Encryption: Encrypting data at rest and in transit to protect it from unauthorized access.
- Data Masking: Masking or anonymizing sensitive data elements to protect privacy while still allowing for data analysis and utilization.
- Compliance: Adhering to data protection regulations such as GDPR and CCPA, ensuring that data is collected, processed, and stored in a compliant manner.
Data Observability: Data observability, which goes beyond traditional monitoring, is becoming increasingly important in DataOps. It involves:
- Comprehensive Monitoring: Collecting and analyzing metrics, logs, and traces from various DataOps components to gain insights into system health, performance, and data
- Proactive Issue Detection: Using AI/ML to identify potential issues and anomalies in data pipelines before they impact downstream processes or users.
- RootCauseAnalysis: Quickly identifying the root cause of issues to enable faster troubleshooting and resolution.
DataOps as a Service (DaaS): The emergence of DaaS offerings provides organizations with a managed DataOps platform, reducing the complexity and overhead of building and maintaining their own infrastructure. DaaS solutions can offer benefits such as:
- Faster Time to Value: Organizations can quickly get started with DataOps without the need for extensive upfront investments in infrastructure and expertise.
- Reduced Operational Overhead: The DaaS provider handles the management and maintenance of the DataOps platform, freeing up internal resources.
- Access to Expertise: DaaS providers often offer expert support and guidance on DataOps best practices and implementation.
These trends highlight the dynamic nature of DataOps and its potential to continue evolving and adapting to the changing needs of the modern enterprise. By staying abreast of these trends and embracing innovation, organizations can ensure that their DataOps practices remain effective and continue to deliver value in the years to come.
Conclusion
The convergence of legacy and modern systems in the contemporary enterprise data landscape presents a complex challenge for organizations seeking to harness the full potential of their data assets. DataOps, with its emphasis on collaboration, automation, and continuous improvement, offers a powerful framework for navigating this complexity and achieving seamless data orchestration. By integrating Data Lakes and Data Lakehouses into their DataOps strategy, organizations can create a unified and scalable data platform that supports a wide range of use cases, from traditional reporting to advanced analytics and machine learning. The successful implementation of DataOps in a hybrid environment requires a strategic approach that addresses the challenges of data integration, quality, and governance. By leveraging technologies such as change data capture, API wrappers, message queues, event-driven integration, microservices integration, and cloud- native integration, organizations can bridge the gap between legacy and modern systems, enabling seamless data flow and analysis.
The adoption of DataOps also necessitates a cultural shift towards collaboration, automation, and continuous improvement. By breaking down silos between data teams, automating repetitive tasks, and implementing CI/CD practices, organizations can accelerate their data operations, improve data quality, and foster innovation.
The benefits of DataOps are numerous, including improved data quality, faster time to insights, increased operational efficiency, and enhanced collaboration. However, organizations must also consider the potential challenges and limitations of DataOps, such as the initial investment, learning curve, and complexity of managing a hybrid environment.
Despite these challenges, the potential rewards of DataOps far outweigh the costs. By enabling organizations to make more informed and timely decisions based on reliable data, DataOps can drive innovation, improve customer experiences, and ultimately lead to a competitive advantage. As the data landscape continues to evolve, DataOps will play an increasingly critical role in enabling organizations to achieve their business objectives through data- driven insights and actions [1-3].
Glossary of Terms
- DataOps: A methodology that applies DevOps principles to the data lifecycle, emphasizing collaboration, automation, and continuous improvement.
- CI/CD: Continuous Integration and Continuous Delivery, a practice that automates the integration, testing, and deployment of code changes.
- Data Integration Layer: A software layer that facilitates the movement and transformation of data between disparate
- Microservices Architecture: An architectural style that structures an application as a collection of loosely coupled
- API: Application Programming Interface, a set of rules and specifications that allow different software applications to communicate with each other.
- Data Virtualization: A technology that creates a unified view of data from multiple sources without the need for physical data replication.
- Metadata: Data that describes other data, providing information about its structure, meaning, and
- Data Lake: A centralized repository for storing vast amounts of raw data in its native format.
- Data Lakehouse: A data architecture that combines the scalability and flexibility of Data Lakes with the data management and ACID transaction capabilities of data warehouses.
References
- Computing Surveys (CSUR) 35: 114-131.
- Hensarling L (2014) AnalyticsOps: Optimizing Data Analytics for Operational
- Palmer A (2015) The DataOps
View PDF