Author(s): Karthika Gopalakrishnan
Predicting loan approval is a critical task in the banking sector, as it affects both financial institutions and loan applicants. Traditional methods often involve a time-consuming and error-prone manual process. This paper explores the application of machine learning algorithms, including KNeighborsClassifier, RandomForestClassifier, Support Vector Classifier (SVC), and Logistics Regression, in predicting loan approval. A comparative analysis of these algorithms is conducted to determine their effectiveness in this domain.
Loan approval is a fundamental process in the banking industry, where financial institutions evaluate the creditworthiness of individuals or businesses seeking financial assistance. The traditional approach to assessing loan applications involves manual review based on predetermined criteria, which can be time- consuming and prone to errors. With the advent of machine learning techniques, there is an opportunity to automate and improve the efficiency and accuracy of loan approval processes.
Machine learning algorithms offer the capability to analyze vast amounts of data and identify patterns that can assist in decision- making processes. In this paper, we explore the application of several machine learning algorithms, namely KNeighborsClassifier, RandomForestClassifier, Support Vector Classifier (SVC), and Logistics Regression, in predicting loan approval. We aim to compare the performance of these algorithms and determine their suitability for this task.
In the pursuit of predicting loan approval statuses within banking systems, the researchers advocate for evaluating the efficacy of diverse classification algorithms, assessing precision, recall, F-measure, and sensitivity metrics [1]. This study scrutinizes the probability of assigning a loan to an individual without incurring financial loss [2]. To achieve this, a multifaceted approach incorporating data from credit bureaus, financial statements, and other pertinent sources will construct a comprehensive applicant profile. Subsequently, this data will train the Random Forest Algorithm, utilizing historical loan data to forecast the likelihood of loan default. By integrating machine learning into this system, the risk associated with loan approval can be mitigated, consequently reducing instances of loan defaults.
The KNeighborsClassifier algorithm is a simple yet effective supervised learning algorithm used for classification tasks. It belongs to the family of instance-based or lazy learning algorithms, where the model is trained by memorizing the training dataset. In the context of loan approval prediction, KNeighborsClassifier calculates the similarity between the input features of a loan applicant and those of previously approved or rejected applications. The decision is then made based on the class labels of the nearest neighbors.
RandomForestClassifier is an ensemble learning method that constructs multiple decision trees during training and outputs the mode of the classes (classification) or the mean prediction (regression) of the individual trees. Each tree in the forest is trained on a random subset of the training data, and predictions are made by aggregating the outputs of all trees. In the context of loan approval prediction, RandomForestClassifier can capture complex relationships between various features and provide robust predictions.
Support Vector Classifier (SVC) is a powerful supervised learning algorithm used for classification tasks. It works by finding the hyperplane that best separates the classes in the feature space. SVC aims to maximize the margin between the classes while minimizing the classification error. In the context of loan approval prediction, SVC can effectively handle high-dimensional feature spaces and nonlinear decision boundaries, making it suitable for complex datasets.
Logistics Regression is a statistical method used for binary classification tasks. Despite its name, it is primarily used for classification rather than regression. Logistics Regression models the probability of a binary outcome (e.g., loan approval or rejection) based on one or more predictor variables. It estimates the probability using a logistic function and makes predictions based on a specified threshold. In the context of loan approval prediction, Logistics Regression offers simplicity and interpretability, making it a popular choice for baseline models.
The information gathered from customers via the loan application serves as the training dataset for model training. This dataset encompasses 13 distinct features, detailed in Table 1 along with their descriptions. Notably, a predominant portion of these variables are categorical, with the majority exhibiting binary categories, as depicted below. Figure 1 offers an overview of the loan dataset.
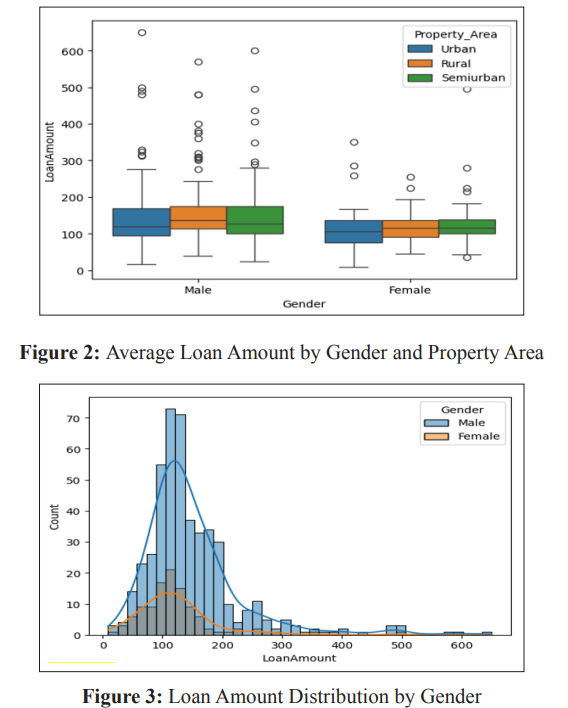
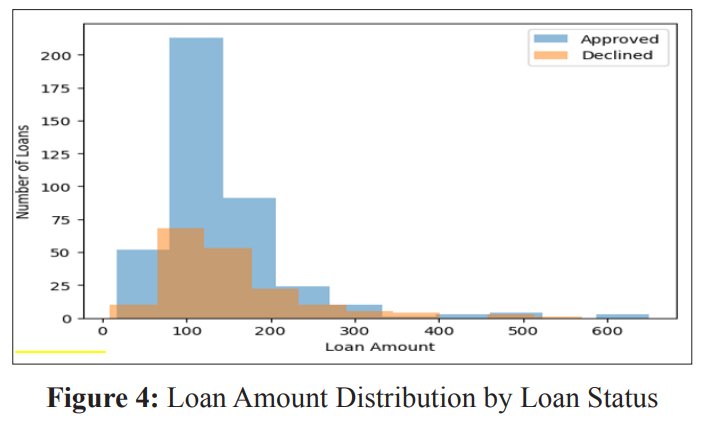
The dataset indicates a higher number of male applicants compared to female applicants, with male applicants seeking loans for higher amounts. Additionally, it reveals a greater demand for loans for properties in urban areas compared to rural areas. Figure 2 illustrates the average loan amount categorized by gender and property area, while Figure 3 displays the distribution of loan amounts across genders. The plot shows that there may be a gender bias in the loan approval process, with women being more likely to be approved for smaller loan amounts than men. Figure 4 displays the distribution of loan amounts based on approval status.
Since the Loan_ID is entirely unique and unrelated to any other column, it will be removed from the dataset. Since all categorical values are binary, we can utilize Label Encoder for these columns, converting the values into integer datatype. Also, missing values, if any, were dropped from the dataset.
The dataset is further split into training and test set. All the mentioned classification models were employed for model training in this study. The model was trained on the training data set and tested on the test data set. Figure 5 illustrates the accuracy scores of the various algorithms on the Test set.
Since the Loan_ID is entirely unique and unrelated to any other column, it will be removed from the dataset. Since all categorical values are binary, we can utilize Label Encoder for these columns, converting the values into integer datatype. Also, missing values, if any, were dropped from the dataset.
The dataset is further split into training and test set. All the mentioned classification models were employed for model training in this study. The model was trained on the training data set and tested on the test data set. Figure 5 illustrates the accuracy scores of the various algorithms on the Test set.

The ROC curve shown in Figure 6 serves as a visual representation of a binary classification model's performance, plotting the true positive rate (TPR) against the false positive rate (FPR) at various classification thresholds. TPR denotes the ratio of correctly classified positive examples, while FPR indicates the ratio of incorrectly classified negative examples. An ideal classifier would exhibit a TPR of 1 and an FPR of 0, represented by a point in the upper left corner of the ROC curve.
In the loan approval prediction model, the ROC curve indicates that the Random Forest classifier achieves the highest TPR and lowest FPR, signifying its superior performance. Comparatively, the KNN classifier demonstrates a lower TPR and higher FPR than the Random Forest classifier but outperforms the SVM and Logistic Regression classifiers. Conversely, the SVM and Logistic Regression classifiers exhibit the lowest TPR and highest FPR, indicating their inferior performance in this task. Table 2 depicts the performance metrics of the different classifiers on the Test set.
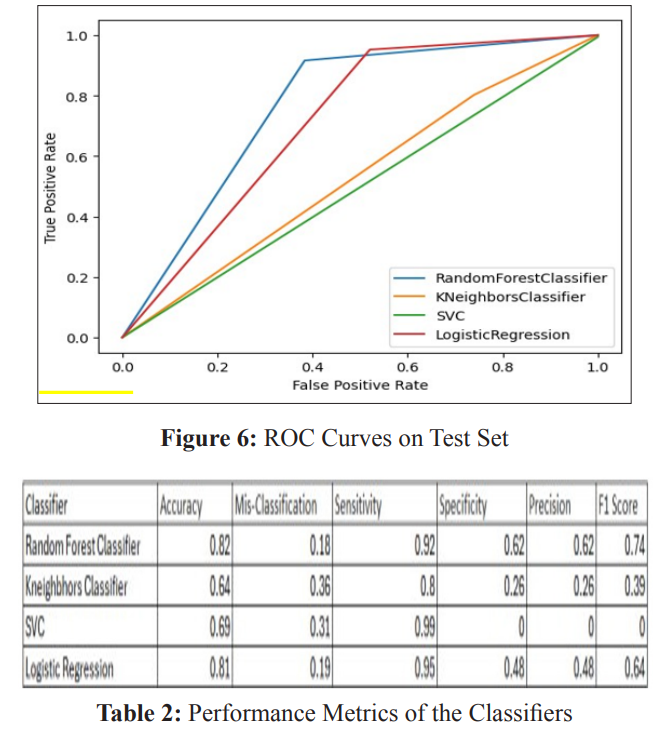
The findings reveal that the Random Forest classifier emerges as the top-performing model for loan approval prediction, boasting an accuracy of 80.77%, sensitivity of 81.82%, and specificity of 79.72%. Following closely, the KNN classifier ranks as the second- best performer, achieving an accuracy of 78.65%, sensitivity of 79.72%, and specificity of 77.59%. Conversely, the SVM and Logistic Regression classifiers exhibit lower accuracies of 76.54% and 74.42%, respectively, positioning them as the least effective models.
The Random Forest classifier excels due to its capacity to discern intricate relationships among data features, enabling precise predictions. While the KNN classifier also captures complex relationships, its sensitivity to data noise renders it slightly less accurate compared to the Random Forest classifier. On the other hand, the SVM and Logistic Regression classifiers lag as they struggle to grasp the complexity of feature relationships within the data.
In conclusion, the Random Forest classifier emerges as the optimal choice for loan approval prediction, offering lenders a robust tool to enhance decision- making accuracy in approving loan applications.