Security Scanning of AI/ML Models in the Software Development Life Cycle
Author(s): Kamalakar Reddy Ponaka
Abstract
Artificial intelligence and machine learning (AI/ML) technologies are transforming the software industry, introducing new capabilities and efficiencies. However, the integration of AI/ML brings forth unique security challenges that must be addressed throughout the Software Development Life Cycle (SDLC). This white paper focuses on best practices and considerations for security scanning in each phase of the SDLC for AI/ML models, providing a roadmap for organizations to secure their AI/ML deployments effectively.
Introduction
AI/ML technologies have grown from experimental tools to core components within a variety of software applications. The specialized nature of AI/ML systems demands rigorous security considerations that are integrated into every stage of the SDLC.
Background
As we design and develop ML systems, it is crucial to recognize and understand various vulnerabilities that these systems may possess. Addressing these weaknesses is an essential part of the security scanning process during the SDLC. Below, we outline several common vulnerabilities that could affect ML models:
- Adversarial Examples: Adversarial examples are inputs to ML models that an attacker has intentionally designed to cause the model to make a mistake. These perturbed inputs are often indistinguishable from regular inputs to the human eye but can deceive models into incorrect predictions.
- Data Poisoning: Data poisoning attacks involve injecting maliciously crafted data into the training set, which can skew the model’s learned behavior. The poisoned data can result in models with biases or that exhibit unwanted behaviors when deployed.
- Model Inversion: Model inversion attacks aim to retrieve sensitive information from ML models. An attacker could use access to a model's predictions to infer details about the training data, potentially violating privacy constraints.
- Membership Inference: Membership inference attacks determine whether a particular data record was used in the training set of an ML This can be a privacy concern, especially if the training data contains sensitive information.
- Model Stealing: Model stealing, or model extraction attacks, occur when an adversary can reconstruct a proprietary ML This can be done by observing the model’s outputs to a series of inputs and reverse-engineering its structure.
- Transfer Learning Vulnerabilities: Transfer learning involves using a pre-trained model as the starting point for a new task. However, the original model’s vulnerabilities can be transferred as well, potentially undermining the new model's
- Evasion Attacks: Evasion attacks happen during the model's inference phase, where the attacker systematically alters malicious samples so that an ML model classifies them incorrectly, thus evading detection.
- Confidence Leakage: Confidence leakage refers to scenarios where the model's confidence in its predictions could provide hints to an attacker on how to modify inputs to change the model's decision.
- Backdoor Attacks: Backdoor, or Trojan attacks, involve embedding a backdoor into an ML model during training, which an attacker can later trigger to cause the model to output predetermined, incorrect results.
These vulnerabilities must be carefully considered during the security scanning processes. Effective defense strategies include adversarial training, robust data validation, frequent retraining, algorithmic transparency, and restricted access to model predictions.
Model Scanning
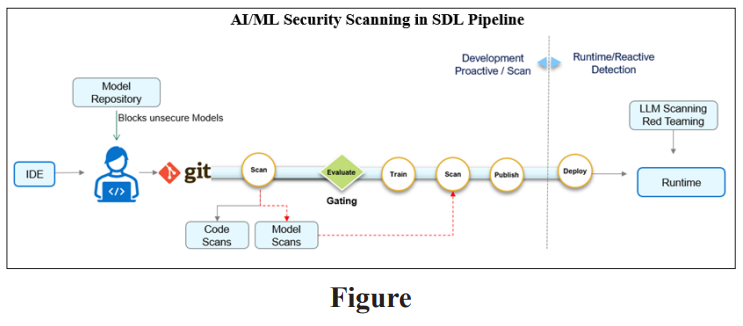
Model scanning is an important scanning technique to detect the vulnerabilities and can be performed during development and CI (Continuous Integration) stage. At the time of writing, there are few scanning tools available to perform this activity and it is expected to mature over a period.
On-Premises vs SaaS Tools for AI/ML Model Scanning Incorporating model scanning in the SDLC for AI/ML systems is a complex decision that involves choosing between on-premises and SaaS solutions. Each option has its own trade-offs in terms of control, cost, scalability, and maintenance.
On-Premises (On-Prem) Tools
Definition: On-prem tools are software solutions that are installed and run on the physical premises of the organization using the software, typically within its own data centers.
Advantages
- Control: Complete control over the tools and the data being processed, ensuring that sensitive information never leaves the organizational environment.
- Customization: Greater flexibility to customize the tool according to specific organizational needs and work flows.
- Security: Potentially higher security assurance, as the organization is responsible for securing its infrastructure.
Disadvantages
- Costs: Higher upfront costs associated with purchasing hardware, software, and maintaining infrastructure.
- Maintenance: Requires a dedicated in-house team for ongoing maintenance, updates, and support.
- Scalability: Scaling up requires additional hardware and can be time-consuming.
Software as a Service (SaaS) Tools
Definition: SaaS tools are third-party applications hosted in the cloud and made available to customers over the internet as a service.
Advantages
- Lower Initial Costs: Typically, SaaS offerings operate on a subscription model, minimizing initial capital
- Ease of Use: Quick and easy setup, as there is no need to install or maintain hardware.
- Scalability: These tools are inherently scalable, easily adjusting to the growing needs of the organization.
- Updates: Continuous and seamless updates are deployed by the service provider, ensuring access to the latest features and security patches.
Disadvantages
- Data Privacy: Data is processed off-site, which might raise concerns about data privacy and security.
- Less Customization: While SaaS tools offer configurability, they might not provide the same level of customization as on-prem solutions.
- Dependency: Reliance on the service provider's uptime and the quality of service; you are affected by outages beyond your control.
Considerations for AI/ML Model Scanning
When selecting tools for AI/ML model scanning, organizations must consider the following:
- Data Sensitivity: If the AI/ML model handles highly sensitive data, on-prem solutions might be preferred due to direct control over the data.
- Regulatory Compliance: Compliance requirements might dictate how and where data can be processed and stored, impacting the choice between on-prem and SaaS.
- Resource Availability: In-house expertise and infrastructure capability will significantly influence the decision.
- Flexibility and Growth: For organizations needing agility and rapid growth, the scalability of SaaS could be a deciding factor.
Recommendations
Ultimately, the choice between on-prem and SaaS for AI/ML model scanning tools depends on the organization's specific needs and constraints. A hybrid approach, using both on-prem and SaaS tools, might be the optimal solution for some, leveraging the advantages of both worlds while mitigating the disadvantages.
Secure Management of ML Models in Repositories
ML model repositories serve as centralized storage for an organization's machine learning models. They facilitate version control, access management, model sharing, and reproducibility. Importantly, these repositories also play a crucial role in the security and governance of ML assets.
Role in the SDLC: Within the SDLC, model repositories support the versioning and tracking of changes to ML models like how code repositories manage software source code. They allow seamless transition through development, testing, and deployment stages while maintaining a clear record of model provenance and alterations.
Core Features of a Secure ML Model Repository
- Version Control: Enables tracking and management of different versions of ML models. Keeps a history of model changes, annotations, and performance metrics.
- Access Control and Permissions: Ensures that only authorized personnel have access to specific models or versions, preventing unauthorized access and potential data breaches.
- Audit Trails: Maintains records of who accessed or modified a model and at what time, providing transparency and facilitating compliance with regulations.
- Model Validation and Testing: Integrates testing frameworks to validate models against predefined metrics and performance bench marks.
- Integration with CI/CD Pipelines: Supports automated model training, validation, and deployment through integration with the CI/CD infrastructure.
- Model Artifacts and Metadata Management: Handles storage of model artifacts, such as weights, parameters, and dependencies, along with relevant metadata like training data schema, hyperparameters, and annotations describing the model’s purpose.
- Security Scanning and Compliance: Automatically scans models and their associated data for vulnerabilities, compliance with security standards, and data privacy regulations.
Establishing a Secure ML Model Repository
- Choosing the Right Platform: Whether using an on-premises solution or a cloud-based service, it's imperative to evaluate the platform's security features and how well they integrate with existing security protocols.
- Data Encryption: Implementing encryption for both data at rest and in transit to ensure that models and training data are secured against unauthorized access.
- Backup and Recovery: Regularly backing up the repository and establishing clear recovery procedures for incidents such as data corruption or loss.
- Regular Updates and Patching: Keeping the repository software updated to patch known vulnerabilities and reduce the risk exposure.
- Monitoring and Anomaly Detection: Continuous monitoring for unauthorized access and anomalies in model behavior, with alerting mechanisms in place.
Challenges in ML Model Repository Management: Managing ML model repositories comes with specific challenges such as ensuring data consistency, securing large volumes of sensitive data, and the overhead of maintaining high availability and disaster recovery capabilities.
Protect Model in Runtime
Understanding LLMs: An LLM is a type of deep learning model that can process, generate, and understand vast amounts of text data. They are pivotal in tasks such as translation, summarization, and predictive text inputs but can also pose risks if not monitored and controlled properly.
The Role of LLM Guard: LLM Guard, a conceptual framework of tools and practices, is proposed to address the unique security and ethical challenges presented by LLMs. Its purpose is multi-fold - enforcing robust security measures, ensuring ethical compliance, and protecting user data.
Components of LLM Guard
- Access Control and Authentication: Strict protocols to verify users and control access to the LLM, ensuring that only authorized individuals interact with the model.
- Usage Monitoring and Logging: Real-time monitoring systems that log all interactions with the LLM to detect and alert on potential misuse or unauthorized activities.
- Output Filtering and Moderation: Tools to automatically filter generated text to prevent the creation and dissemination of harmful content.
- DataPrivacyMeasures: Mechanisms for anonymizing and encrypting data to uphold privacy standards and compliance with regulations such as GDPR.
- Bias Detection and Mitigation: Continuous assessments of the LLM's outputs to identify and correct biases within the model.
- EthicalTrainingGuidelines: A set of training policies that emphasize the importance of ethical considerations in LLM development, ensuring that the model training process is transparent, fair, and inclusive.
Integration of LLM Guard in the SDLC: Embedding the LLM Guard best practices within the SDLC is crucial for responsible AI development. It ensures that security and ethical considerations are incorporated from the outset and throughout the model's lifecycle.
Challenges and Considerations: Implementing security measures for LLMs is not without its challenges, including staying ahead of potential threats, managing the scale of data necessary for LLMs, and constantly updating measures to keep up with evolving models.
Model Redteaming
Red teaming is an adversarial approach traditionally used in security domains to test and improve security measures by simulating attacks that a real-world adversary could carry out. When applied to ML models, red teaming involves simulating adversarial attacks on the models to anticipate and prevent exploits post-deployment.
The Necessity of Red Teaming for ML Models: As ML models become increasingly integrated into critical systems, the impact of potential security breaches grows. Red teaming exercises can uncover latent vulnerabilities in ML systems that standard testing procedures might not detect. By rigorously evaluating model security from an attacker's perspective, organizations can better understand and fortify their ML defenses.
Strategies for ML Model Red Teaming
- Adversarial Attacks
- Craft and deploy data inputs designed to mislead ML models (e.g., adversarial images to fool computer vision systems).
- Test the model's resilience to various adversarial attack techniques to identify potential weaknesses.
2. Data Poisoning and Inference Attacks
- Evaluate the model's vulnerability to poisoning attacks that introduce subtly corrupted training data, affecting the model's learning process and compromising its
- Perform inference attacks aiming to reverse-engineer training data from model outputs, potentially revealing sensitive information.
3. Model and Algorithm Exploitation
- Identify and exploit potential flaws within the ML algorithms,such as overfitting or underfitting.
- Attempt to create or expose backdoors that could trigger the model to make incorrect predictions when presented with certain inputs.
4. Policy and Compliance Violation Testing
- Test the adherence of ML models to relevant regulations and policies, such as GDPR for data privacy and HIPAA for healthcare-related data.
- Validate that the model does not produce discriminatory or biased results.
Benefits of Integrating Red Teaming in the SDLC: A proactive red teaming approach integrated within the SDLC enables the early identification of risks, informs better model design, and supports the development of stronger defense mechanisms.
Challenges and Best Practices: Red teaming is a complex activity and may pose several challenges, including resource intensity, the creativity required to simulate novel threats, and the potential disruption of regular development workflows. Best practices include:
- Conducting red teaming exercises periodically and after significant changes to the model or its operating
- Utilizing interdisciplinary teams with diverse backgrounds to simulate a broad range of attack scenarios.
- Documenting insights and learnings from red team exercises and translating them into concrete security improvements.
Conclusion
Integrating security scanning into CI/CD pipelines is a critical strategy for maintaining a high security posture in AI/ML applications. Proper implementation can help in catching vulnerabilities early, reducing the potential for security incidents, and promoting a culture of security mindfulness among development teams [1-20].
A secure ML model repository is fundamental to managing the AI/ ML assets within an organization's SDLC. By incorporating robust security features and best practices for access control, versioning, and compliance, organizations can establish a solid foundation for the secure development, deployment, and maintenance of their machine learning models.
As LLMs continue to grow in capabilities and influence, the necessity of concepts like LLM Guard becomes increasingly evident. The industry must commit to proactive measures that guard against the inherent risks while leveraging the substantial benefits of LLMs.
Red teaming exercises are critical for preparing ML models against sophisticated threats. They offer a valuable layer of scrutiny that can significantly improve the robustness and security of deployed ML systems.
References
- Shalev-Shwartz S, Ben-David S (2014) Understanding Machine Learning: From Theory to Cambridge University Press.
- Kurakin A, Goodfellow I, Bengio (2017) Adversarial examples in the physical world in Proc. International Conference on Learning Representations.
- Papernot N, McDaniel P, Swami A, Harang R (2016) Crafting adversarial input sequences for recurrent neural networks in Proc. IEEE Military Communications Conference (MILCOM).
- Akhtar Z, Mian A (2018) Threat of adversarial attacks on deep learning in computer vision: A IEEE Access 6: 14410-14430.
- Fredrikson M, Jha S, Ristenpart T (2015) Model inversion attacks that exploit confidence information and basic countermeasures in Proc. ACM SIGSAC Conference on Computer and Communications Security.
- Chen T, Zhang H, Zhao M, Leibe B, Wei X, et al. (2016) TensorFlow: A system for large-scale machine learning in USENIX Symposium on Operating Systems Design and Implementation (OSDI).
- Brynielsson J, Horndahl A, Johansson F, König L, Mårtensson D, et al. (2014) Detecting social engineering attacks using machine-learning techniques in Proc. IEEE International Conference on Intelligence and Security Informatics (ISI).
- Hitaj B, Ateniese G, Pérez-Cruz F (2017) Deep models under the GAN: Information leakage from collaborative deep learning in Proc. ACM SIGSAC Conference on Computer and Communications Security.
- Voigt M, Von dem Bussche A (2017) The EU General Data Protection Regulation (GDPR)
- Papernot N, McDaniel P, Wu X, Jha S, Swami A (2016) Distillation as a defense to adversarial perturbations against deep neural networks in IEEE Symposium on Security and Privacy (SP).
- Russell S, Norvig P (2009) Artificial Intelligence: A Modern Approach 3rd ed. Prentice
- Goodfellow I, Bengio Y, Courville A (2016) Deep MIT Press. https://www.deeplearningbook.org/.
- Kurakin A, Goodfellow I, Bengio S (2017) Adversarial examples in the physical world in International Conference on Learning Representations (ICLR).
- Anuar NB (2020) Data Poisoning Attacks in Machine IEEE Access 8: 67591-67612.
- Eykholt K (2017) Robust physical-world attacks on machine learning Ar Xiv Preprint Ar Xiv: 1707.08945.
- Papernot N (2016) The limitations of deep learning in adversarial settings in IEEE European Symposium on Security and Privacy DOI: https://doi.org/10.48550/arXiv.1511.07528.
- Wu et Z (2018) Towards Privacy-Preserving Visual Recognition via Adversarial Training: A Pilot Study in IEEE Conferenc on Computer Vision and Pattern Recognition (CVPR).
- Szegedy C (2013) Intriguing properties of neural networks. ar Xiv Preprint ar Xiv: 6199.
- European Union General Data Protection Regulation (GDPR) https://eur-lex.europa.eu/eli/reg/2016/679/oj.
- Ateniese G (2015) Hacking Smart Machines with Smarter Ones: How to Extract Meaningful Data from Machine Learning Classifiers, International Journal of Security and Networks 10: 137-150.
View PDF