The Power of Cloud-Native Solutions for Descriptive Analytics: Unveiling Insights from Data
Author(s): Ramakrishna Manchana
Abstract
Descriptive analytics, the foundation of data-driven decision-making, has been revolutionized by the advent of cloud-native technologies. This paper explores the role of cloud-native solutions in empowering descriptive analytics, examining its architectural components, benefits, challenges, and realworld applications. We discuss the offerings of major cloud vendors, best practices for implementation, and future trends in this field.
Introduction
In today's data-driven world, organizations across industries generate massive volumes of data at an unprecedented rate. Descriptive analytics, which focuses on understanding past trends and patterns, plays a pivotal role in extracting valuable insights from this data deluge. It empowers businesses to answer questions like "What happened?", "How often does it happen?", and "Where is the problem?". Traditionally, descriptive analytics has faced challenges related to data volume, complexity, and accessibility. The rise of cloud computing has presented a transformative solution to these hurdles.
Cloud-native solutions, designed specifically for cloud environments, offer unparalleled scalability, flexibility, and cost-efficiency. They enable organizations to leverage the vast computational and storage resources of the cloud to perform descriptive analytics at scale. These solutions encompass a range of architectural components, including data storage, processing, orchestration, and visualization tools, all working in concert to facilitate the extraction, transformation, and presentation of insights from data.
This paper delves into the power of cloud-native solutions for descriptive analytics. We explore the architectural components that underpin these solutions, highlighting their key features and benefits. We examine the advantages they offer in terms of scalability, cost-efficiency, agility, and collaboration. We also address the challenges and considerations associated with adopting cloud-native solutions, such as data governance, vendor lock-in, and skills gap.
Furthermore, we provide an overview of the offerings from major cloud vendors for descriptive analytics, along with best practices for successful implementation. Finally, we look ahead to the future trends that are shaping the landscape of descriptive analytics in the cloud. By understanding the potential of cloud-native solutions, organizations can unlock the full value of their data and gain a competitive edge in today's dynamic business environment.
Literature Review
The field of descriptive analytics has evolved significantly over the years, driven by advancements in technology and the increasing availability of data. Early research focused on statistical methods and data mining techniques to extract insights from structured data [1]. With the rise of big data and the proliferation of unstructured data sources, the focus shifted towards scalable and distributed computing frameworks [2].
Cloud computing has emerged as a key enabler of descriptive analytics, offering virtually unlimited storage and processing capabilities. Several studies have explored the benefits of cloud- based solutions for descriptive analytics, highlighting their scalability, cost-efficiency, and agility. For instance, research by Abadi et al. demonstrates how cloud-based data warehouses can handle massive volumes of data and support complex queries, enabling organizations to perform descriptive analytics at scale [3].
Furthermore, the literature emphasizes the role of cloud-native technologies in enhancing descriptive analytics. Cloud-native solutions, designed specifically for cloud environments, leverage the elasticity and pay-as-you-go pricing models of the cloud to provide cost-effective and scalable analytics capabilities. A study by Baldini et al. showcases how serverless computing can enable on-demand data processing for descriptive analytics, reducing infrastructure costs and improving resource utilization [4].
However, the adoption of cloud-native solutions for descriptive analytics also presents challenges. Data governance, security, and compliance remain critical concerns, especially when dealing with sensitive data. Research by Pearson underscores the importance of implementing robust data governance frameworks and security measures to ensure data privacy and regulatory adherence in cloud environments [5].
In addition, the literature highlights the need for organizations to develop cloud-native skills and expertise to effectively leverage these solutions. A survey by RightScale reveals a significant skills gap in cloud technologies, emphasizing the importance of training and upskilling employees to maximize the benefits of cloud-native descriptive analytics [6].
Overall, the existing literature provides a strong foundation for understanding the potential of cloud-native solutions for descriptive analytics. It highlights the advantages, challenges, and best practices associated with adopting these solutions. As cloud technologies continue to evolve, further research is needed to explore emerging trends and their impact on the future of descriptive analytics in the cloud.
Cloud Native Architecture Components of Descriptive Analytics Cloud-native solutions leverage a variety of architectural components to facilitate the collection, storage, processing, and visualization of data for descriptive analytics. These components are designed to work seamlessly in cloud environments, offering scalability, flexibility, and cost-efficiency. Let's explore some of the key components:
Data Storage:
- Data Lakes: Cloud-based data lakes provide a centralized repository for storing vast amounts of structured, semi- structured, and unstructured data. They offer scalability, durability, and support for various data formats, making them ideal for storing raw data for descriptive analytics. Popular cloud data lake solutions include Amazon S3, Azure Data Lake Storage, and Google Cloud Storage.
- Data Warehouses: Cloud data warehouses are optimized for storing and querying structured They offer powerful analytical capabilities, including support for complex SQL queries and data aggregation. They enable efficient data exploration and analysis for descriptive analytics. Prominent cloud data warehouse solutions include Amazon Redshift, Azure Synapse Analytics, and Google BigQuery.
- Data Lakehouses: A data lakehouse combines the best features of data lakes and data warehouses, offering a unified platform for storing and analyzing structured, semi-structured, and unstructured data. It enables organizations to perform descriptive analytics on a wide range of data types without the need for complex data movement or Examples of cloud-based data lakehouse solutions include Databricks Delta Lake and AWS Lake Formation.
- Cloud-Agnostic Data Storage: Several solutions provide cloud-agnostic data storage, allowing you to store data in a format that can be accessed and used across multiple cloud These solutions often leverage open-source technologies or provide APIs that facilitate interoperability.
Data Processing:
- ServerlessComputing: Serverless computing allows for on- demand execution of code in response to events or It eliminates the need for managing servers, providing scalability and cost-efficiency for data processing tasks in descriptive analytics. Major cloud providers offer serverless computing services like AWS Lambda, Azure Functions, and Google Cloud Functions.
- ManagedServices: Cloud providers offer managed services for various data processing tasks, such as data transformation, cleaning, and aggregation. These services abstract the complexities of infrastructure management, allowing users to focus on the analytics Examples include AWS Glue, Azure Data Factory, and Google Cloud Dataflow.
- Batch Processing: Suitable for analyzing large datasets at scheduled intervals, batch processing is commonly used for generating reports, performing data transformations, and training machine learning models.
- Stream Processing (Near-Real-Time): Enables real-time or near-real-time insights from streaming data, allowing for immediate actions or alerts based on incoming data.
- Time Series Processing: Cloud-native solutions also support specialized time series databases or libraries for efficient storage and analysis of time-stamped data. These enable organizations to identify trends, seasonality, and other patterns in data that changes over time.
Data Orchestration:
- Workflow Management Tools: Workflow management tools automate the scheduling and coordination of data pipelines for descriptive They help streamline data ingestion, transformation, and loading processes, ensuring data is readily available for analysis. Popular cloud-based workflow management tools include Apache Airflow, AWS Step Functions, and Azure Data Factory.
- Cloud-Agnostic Data Orchestration: Some workflow management tools offer cloud-agnostic capabilities, enabling you to orchestrate data pipelines across multiple cloud These tools typically support hybrid and multi- cloud deployments, providing flexibility and avoiding vendor lock-in.
Data Visualization and BI:
- Cloud-Based BI Tools: Cloud-based business intelligence (BI) tools provide interactive dashboards, reports, and visualizations to present descriptive insights in a meaningful and actionable They enable users to explore data, identify trends, and communicate findings effectively. Leading cloud BI tools include Amazon QuickSight, Microsoft Power BI, and Google Looker.
- Cloud-Agnostic BI Tools: Certain BI tools are designed to connect to and visualize data from various cloud providers, offering a unified view of your data regardless of where it's
These architectural components, working in concert, empower organizations to leverage the power of cloud-native solutions for descriptive analytics. By providing scalable, flexible, and cost- effective capabilities, they enable businesses to gain valuable insights from their data, drive informed decision-making, and achieve their strategic objectives.
Benefits of Cloud Native Solutions for Descriptive Analytics Cloud-native solutions offer a multitude of advantages for organizations seeking to leverage descriptive analytics to gain insights from their data. These benefits stem from the inherent characteristics of cloud computing and the design principles of cloud-native technologies. Let's explore some of the key advantages:
- Scalability and Elasticity: Cloud-native solutions are designed to scale horizontally, allowing organizations to easily handle growing data volumes and fluctuating workloads. They can dynamically provision or de-provision resources based on demand, ensuring optimal performance and cost-efficiency. This scalability empowers organizations to perform descriptive analytics on massive datasets without the limitations of on-premises infrastructure.
- Cost-Efficiency: Cloud computing operates on a pay-as-you- go pricing model, enabling organizations to pay only for the resources they This eliminates the need for upfront capital investments in hardware and software. Additionally, cloud-native solutions often leverage serverless computing and managed services, further reducing infrastructure costs and operational overhead.
- Agility and Accessibility: Cloud-native solutions provide a flexible and agile environment for descriptive analytics. They enable organizations to quickly spin up new analytics environments, experiment with different tools and techniques, and iterate on their analyses. Moreover, cloud-based solutions offer easy accessibility to data and analytics tools from anywhere with an internet connection, promoting collaboration and data democratization.
- Collaboration: Cloud-native solutions facilitate collaboration among teams and individuals across different Data and analytics tools can be shared seamlessly, allowing for real-time collaboration on data exploration, analysis, and visualization. This fosters knowledge sharing and accelerates the discovery of insights.
- Reliability and Security: Cloud providers invest heavily in infrastructure redundancy, data replication, and security measures to ensure high availability and data protection. Cloud-native solutions inherit these built-in features, providing organizations with a reliable and secure environment for descriptive analytics.
These benefits collectively empower organizations to leverage descriptive analytics effectively. By harnessing the power of cloud- native solutions, businesses can gain a deeper understanding of their data, identify trends, uncover opportunities, and make informed decisions that drive growth and success.
Cloud Vendor Offerings
Major cloud providers offer a rich ecosystem of services and tools tailored for descriptive analytics. These offerings are categorized based on their architectural components, catering to diverse needs from data storage and processing to visualization and business intelligence. Let's explore some prominent examples from each major cloud provider:
Amazon Web Services (AWS) Data Storage
- Data Warehousing: Amazon Redshift
- Data Lakes: Amazon S3
- Data Lakehouses: AWS Lake Formation
Data Processing
- Serverless Computing: AWS Lambda
- Managed Services: AWS Glue, Amazon EMR
- Batch and Stream Processing: Amazon Kinesis, AWS Batch
- Time Series Processing: Amazon Timestream
Data Visualization and BI
- BI and Visualization: Amazon Quick Sight
Microsoft Azure
Data Storage
- Data Warehousing: Azure Synapse Analytics
- Data Lakes: Azure Data Lake Storage
- Data Lakehouses: Databricks on Azure
Data Processing
- Serverless Computing: Azure Functions
- Managed Services: Azure Data Factory, Azure HDInsight
- Batch and Stream Processing: Azure Stream Analytics, Azure Data Lake Analytics
- Time Series Processing: Azure Time Series Insights
Data Visualization and BI
- BI and Visualization: Power BI
Google Cloud Platform (GCP)
Data Storage
- Data Warehousing: Big Query
- Data Lakes: Google Cloud Storage
- Data Lakehouses: Dataproc Metastore & Apache Hudi on GCP
Data Processing
- Serverless Computing: Google Cloud Functions
- Managed Services: Google Cloud Dataflow, Google Cloud Dataproc
- Batch and Stream Processing: Google Cloud Datastream, Google Cloud Pub/Sub
Data Visualization and BI
- BI and Visualization: Looker
Cloud-Agnostic Solutions
In addition to the cloud-specific offerings mentioned earlier, several cloud-agnostic solutions exist for descriptive analytics. These solutions may be deployed on any cloud provider or even on-premises, providing organizations with greater flexibility and control over their data and infrastructure. Examples of cloud- agnostic solutions include:
- Data Warehousing: Snowflake
- Data Lakes: Apache Hadoop, Apache Spark
- BI and Visualization: Tableau, QlikView
- Time Series Databases: InfluxDB, TimescaleDB
The specific choice of cloud vendor and services depends on various factors, including organizational requirements, existing technology stack, budget considerations, and desired features. It's crucial to carefully evaluate the offerings from different providers and select the ones that best align with your descriptive analytics needs.
Implementation of Cloud-Native Analytics
This section explores how various cloud vendor offerings can be leveraged for batch processing, stream processing (near-real- time), and time-series analytics within the context of descriptive analytics. We'll organize the information by cloud provider to provide a clearer overview of each platform's capabilities.
Amazon Web Services (AWS) Batch Processing
In the AWS batch processing architecture, data is ingested from various sources using AWS Glue for ETL. It is then stored in either Amazon S3 (Data Lake) or Amazon Redshift (Data Warehouse). Processing is handled by AWS Batch or triggered by AWS
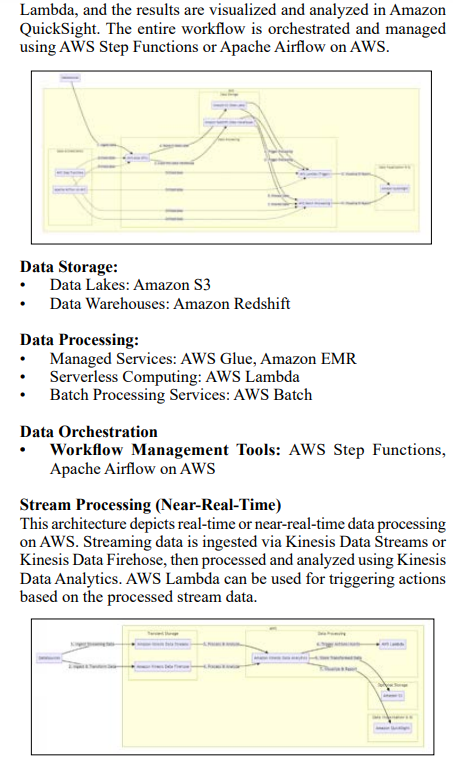
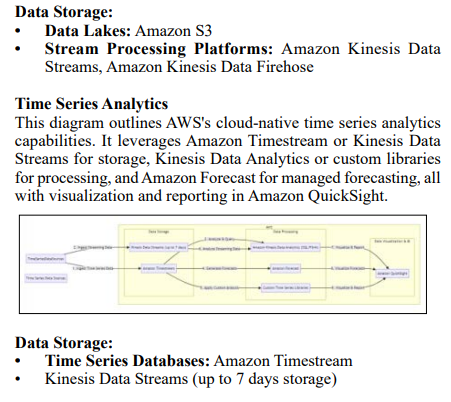



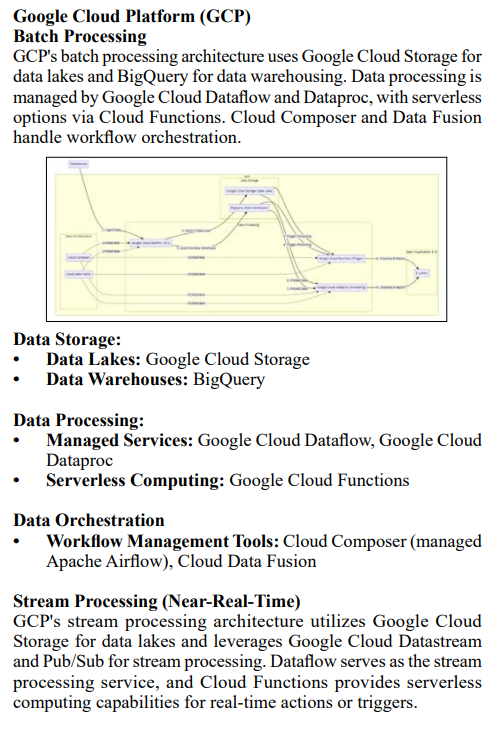



Batch Processing Data Storage:
- GoogleCloudStorage: Used to store raw and historical data related to shipments, orders, invoices, and other operational
- BigQuery: Employed as a data warehouse to store structured and aggregated data for efficient querying and analysis.
Data Processing:
- Google Cloud Dataflow: Utilized for ETL processes, transforming and loading data from various sources into
- Google Cloud Dataproc: Leveraged for running batch processing jobs on Apache Spark clusters for complex data transformations and aggregations.
- Google Cloud Functions: Used to trigger batch processing jobs based on schedules or specific events.
Data Orchestration:
- Cloud Composer: Managed Apache Airflow service used to orchestrate and schedule batch processing workflows, ensuring data is consistently and reliably processed.
Insights Generated:
KPI Dashboards: Visualizing key metrics like on-time delivery rates, transportation costs, and carrier performance to track progress and identify areas for improvement.
Shipment Analysis Reports: Generating detailed reports on shipment volumes, routes, and costs to understand historical patterns and trends.
Carrier Performance Analysis: Evaluating carrier performance based on historical data to identify top-performing carriers and optimize carrier selection.
Stream Processing (Near-Real-Time) Data Storage:
- Google Cloud Storage: Used to archive streaming data for long-term retention and analysis.
- GoogleCloudPub/Sub: Employed as a real-time messaging service to ingest and buffer streaming data from various sources, such as IoT devices and tracking systems.
Data Processing:
- Google Cloud Dataflow: Leveraged to process and analyze streaming data in near-real-time, enabling the company to monitor shipments, track assets, and identify potential
- Google Cloud Functions: Used to trigger real-time actions or alerts based on events detected in the streaming data.
Insights Generated:
Real-time Shipment Tracking: Providing live updates on shipment locations and ETAs to customers and internal stakeholders.
ProactiveExceptionManagement: Identifying potential delays or disruptions in real-time and triggering alerts or corrective actions.
Dynamic Route Optimization: Adjusting routes based on real- time traffic and weather conditions to minimize delays and improve efficiency.
Time Series Analytics Data Storage:
- DataprocMetastore&Apache Hudi on GCP: Employed as a data lakehouse solution to store and manage time-series data related to shipment tracking, asset location, and sensor
- Google Cloud Pub/Sub (with limitations): Used for short- term retention of streaming data for near-real-time time-series
Data Processing:
- CustomTimeSeriesLibraries(e.g.,Pandas,Statsmodels): Utilized within Dataflow or Dataproc jobs to perform complex time-series analysis, such as forecasting demand, predicting delays, and identifying anomalies.
Insights Generated:
Demand Forecasting: Predicting future demand for various products or routes to optimize inventory levels and transportation capacity.
Predictive ETA: Estimating accurate ETAs based on historical patterns and real-time conditions, improving customer communication and satisfaction.
Anomaly Detection: Identifying unusual patterns or outliers in shipment data to proactively detect potential issues or fraud.
Benefits
By adopting cloud-native descriptive analytics solutions on GCP, the leading logistics & supply chain company has achieved the following benefits:
Scalability: The ability to handle massive volumes of data and scale resources on-demand has enabled them to accommodate growing data needs and support a large user base.
Cost-Efficiency: The pay-as-you-go pricing model and the use of serverless computing have helped optimize costs and avoid upfront infrastructure investments.
Agility: The flexibility and agility of cloud-native solutions have allowed them to quickly iterate on their analytics models and respond to changing business requirements.
Collaboration: Cloud-based tools and shared access to data have fostered collaboration across teams and departments, enabling faster and more informed decision-making.
Real-time Insights: Stream processing and time-series analytics have empowered the company to gain near-real-time insights into their supply chain operations, allowing them to proactively address disruptions and optimize their processes.
Conclusion
This successful implementation of cloud-native descriptive analytics on GCP demonstrates the transformative power of these solutions for supply chain and logistics companies. By leveraging the scalability, cost-efficiency, and agility of the cloud, the company has gained valuable insights from its data, enabling it to optimize its operations, improve customer satisfaction, and maintain its leadership position in the industry.
Case Study: Cloud-Native Descriptive Analytics at a Leading Beverage Company
Company Overview
A leading beverage company, known for its diverse portfolio of refreshing drinks, sought to enhance its supply chain visibility and optimize its shipment scheduling and maintenance processes. Recognizing the power of data-driven decision-making, the company embarked on a journey to implement cloud-native descriptive analytics solutions.
Challenge
The beverage company faced the complex challenge of managing and analyzing vast amounts of data related to its shipment scheduling and maintenance operations. This data included:
- Shipment Details: Comprehensive information about each shipment, including origin, destination, product type, quantity, scheduled delivery dates, and carrier details.
- Maintenance Records: Historical maintenance records for transportation assets like trucks and delivery vehicles, including repair logs, service history, and part
- Inventory Data: Real-time updates on inventory levels at various warehouses and distribution centers.
Sales Data: Sales figures for different products across various regions and time periods.
The company needed to leverage descriptive analytics to gain insights into key performance indicators (KPIs) such as on-time delivery rates, shipment delays, maintenance costs, and inventory turnover. This information was critical for identifying bottlenecks, optimizing shipment schedules, improving asset maintenance practices, and aligning production with demand.
Solution
The company adopted a cloud-native approach to descriptive analytics, harnessing the capabilities of Microsoft Azure. They implemented various architectural components and services to process and analyze their data effectively.
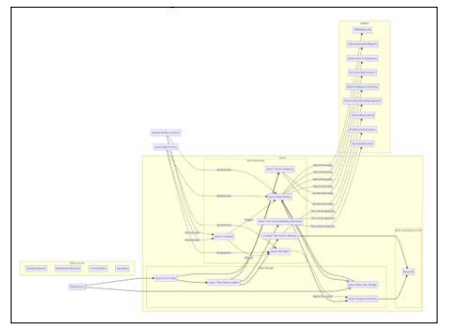
Batch Processing Data Storage:
- Azure Data Lake Storage: Used as a centralized repository to store raw and historical data from various sources, including shipment logs, maintenance records, inventory systems, and sales databases.
- Azure Synapse Analytics: Employed as a data warehouse to store structured and aggregated data, enabling efficient querying and analysis.
Data Processing:
- Azure Data Factory: Used for ETL processes, extracting, transforming, and loading data from disparate sources into the data lake and data warehouse.
- Azure HDInsight: Leveraged to run batch processing jobs using Apache Spark or Hadoop clusters for complex data transformations and aggregations.
- AzureFunctions: Employed to trigger batch processing jobs based on schedules or specific events, ensuring timely data updates and analysis.
Data Orchestration
- Azure Data Factory: Orchestrated the entire batch processing workflow, including data ingestion, transformation, loading, and analysis tasks.
Stream Processing (Near-Real-Time) Data Storage:
- Azure Data Lake Storage: Used to archive streaming data for future batch analysis and long-term retention.
- AzureEventHubs: Served as a highly scalable data ingestion service for capturing real-time events and telemetry data from IoT devices, sensors, and tracking systems.
Data Processing:
- AzureStreamAnalytics: Processed and analyzed streaming data in near-real-time, allowing the company to monitor shipment progress, track asset locations, and detect potential issues or delays.
- Azure Functions: Triggered real-time notifications and alerts based on anomalies or critical events detected in the streaming data.
Time Series Analytics Data Storage:
- AzureTime Series Insights: Used to store and analyze time- series data related to shipment tracking, inventory levels, and sales trends.
- Azure Event Hubs (up to 7 days storage): Retained recent streaming data for short-term time-series analysis.
Data Processing:
- AzureStreamAnalytics: Performed time-series analysis on streaming data, enabling the company to identify patterns, trends, and anomalies in real-time.
- CustomTimeSeriesLibraries(e.g.,Pandas,Statsmodels): Integrated with Azure services to conduct advanced time- series analysis and forecasting on historical data stored in the data lake or data warehouse.
- Azure Time Series Anomaly Detection: Leveraged to automatically detect anomalies in time-series data, aiding in proactive issue identification and resolution.
Data Visualization and BI:
Power BI: Connected to Azure Synapse Analytics and other data sources to create interactive dashboards, reports, and visualizations, empowering stakeholders to explore and understand key insights.
Benefits
By adopting cloud-native descriptive analytics solutions on Azure, the beverage company has achieved significant benefits:
- ImprovedSupplyChainVisibility: Real-time tracking and monitoring of shipments enable proactive issue resolution and enhance customer satisfaction.
- Optimized Shipment Scheduling: Analyzing historical shipment data and demand patterns allows for efficient scheduling and resource allocation.
- Predictive Maintenance: Analyzing equipment sensor data and maintenance logs helps predict potential failures, reducing downtime and maintenance costs.
- Inventory Optimization: Understanding inventory levels and sales trends facilitates better inventory management and reduces carrying costs.
- Enhanced Decision-Making: Access to real-time insights and interactive visualizations empowers stakeholders to make informed decisions that drive operational efficiency and cost savings.
Conclusion
This implementation of cloud-native descriptive analytics on Azure exemplifies how a leading beverage company transformed its supply chain operations. By harnessing the power of the cloud, they gained a competitive edge by optimizing shipment scheduling, improving asset maintenance, and aligning production with demand.
Challenges
While cloud-native solutions offer numerous benefits for descriptive analytics, their adoption also presents certain challenges that organizations need to address. These challenges encompass various aspects, from data management and security to performance optimization and skillset development. Let's explore some of the key challenges:
- Data Quality and Integration: Ensuring data accuracy, consistency, and completeness across disparate sources is a critical challenge. Data from various systems may have different formats, structures, and levels of quality. Integrating and cleaning this data to create a unified view for descriptive analytics can be complex and time-consuming.
- Security and Compliance: Protecting sensitive data and adhering to regulatory requirements are paramount concerns in cloud environments. Organizations need to implement robust security measures, including data encryption, access controls, and vulnerability management, to safeguard their Additionally, they must ensure compliance with industry- specific regulations and data privacy laws.
- PerformanceOptimization: Achieving optimal performance for descriptive analytics workloads in the cloud requires careful planning and Factors such as data partitioning, query optimization, and resource allocation can significantly impact performance. Organizations need to monitor and optimize their cloud environments to ensure efficient data processing and analysis.
- SkillsetGap: Acquiring and retaining cloud-native expertise can be a challenge for many Cloud technologies evolve rapidly, and keeping up with the latest developments requires continuous learning and upskilling. Organizations need to invest in training and development programs to build a skilled workforce capable of leveraging cloud-native solutions effectively.
- Vendor Lock-in: While cloud-agnostic solutions mitigate vendor lock-in, organizations still need to carefully evaluate the portability of their data and applications when adopting cloud-native It is important to choose solutions and architectures that allow for flexibility and avoid being tied to a single cloud provider.
- CostManagement: While cloud solutions offer the potential for cost savings, it is crucial to manage cloud resources effectively to avoid unexpected expenses. Organizations need to monitor usage, optimize resource allocation, and implement cost control measures to ensure that cloud costs remain predictable and aligned with their budget.
Best Practices
To maximize the benefits of cloud-native solutions for descriptive analytics, organizations should adhere to certain best practices that encompass data governance, automation, cost optimization, and continuous learning. Let's delve into some key recommendations: Data Governance:
- Establish clear policies and procedures for data This includes defining data ownership, access controls, data quality standards, and data retention policies.
- Implement a data catalog or metadata repository to provide a centralized view of available data assets, their lineage, and their relationships.
- Ensure compliance with industry-specific regulations and data privacy laws by implementing appropriate security measures and data anonymization or pseudonymization techniques.
Automation:
- Leverage automation for data ingestion, transformation, and visualization to streamline workflows, reduce manual errors, and accelerate time-to-insight.
- Utilize cloud-native orchestration tools to automate data pipelines, ensuring data is consistently and reliably processed for descriptive analysis.
- Employ infrastructure-as-code (IaC) practices to automate the provisioning and management of cloud resources, promoting consistency and repeatability.
Cost Optimization:
- Monitor and optimize resource usage to control Utilize cloud cost management tools to track spending, identify cost-saving opportunities, and implement strategies such as rightsizing instances, utilizing reserved instances or savings plans, and leveraging spot instances for non-critical workloads.
- Adopt a "pay-as-you-go" approach to cloud resource provisioning, scaling resources up or down based on actual
- Consider using serverless computing for event-driven or sporadic workloads to avoid paying for idle resources.
Continuous Learning:
- Cloud technologies evolve rapidly, and staying updated on the latest developments is essential. Organizations should invest in training and development programs to upskill their teams on cloud-native technologies and best practices.
- Encourage a culture of continuous learning and experimentation, allowing teams to explore new tools and techniques to enhance their descriptive analytics
Multi-Cloud Strategy:
- Consider adopting a multi-cloud strategy to avoid vendor lock- in and leverage the strengths of different cloud This approach can also provide greater resilience and flexibility in case of outages or service disruptions.
- Choose cloud-agnostic solutions whenever possible to ensure portability and interoperability across different cloud By adhering to these best practices, organizations can ensure the successful implementation and ongoing optimization of their cloud-native descriptive analytics solutions. These practices promote data quality, efficiency, security, and cost-effectiveness, ultimately enabling organizations to derive maximum value from their data.
Future Trends
The future of descriptive analytics in the cloud is poised for exciting advancements, driven by emerging trends that promise to further enhance its capabilities and impact. Let's explore some key trends:
- ServerlessAnalytics: The adoption of serverless architectures for descriptive analytics is expected to grow, offering even greater scalability, cost-efficiency, and operational simplicity. Serverless analytics allows organizations to focus on their analytics logic without worrying about infrastructure management, scaling, or maintenance.
- AI-Augmented Analytics: The integration of artificial intelligence (AI) and machine learning (ML) with descriptive analytics will enable automated insights discovery, anomaly detection, and enhanced data AI-powered tools can automatically identify patterns, trends, and outliers in data, providing users with actionable insights without the need for manual analysis.
- Real-time Analytics:The demand for near-real-time insights from streaming data will continue to rise, driving the development of cloud-native solutions that can process and analyze data in real-time. Real-time analytics empowers organizations to make timely decisions based on the latest data, improving operational efficiency and responsiveness.
- Edge Analytics: Processing and analyzing data closer to the source, at the edge of the network, will become increasingly important for applications that require low latency and real-time responsiveness. Edge analytics can reduce data transmission costs, improve data privacy, and enable real- time decision-making in scenarios where connectivity to the cloud may be limited or unreliable.
- Hybrid and Multi-Cloud Analytics: The increasing adoption of hybrid and multi-cloud environments will drive the demand for cloud-agnostic and interoperable analytics solutions. Organizations will seek solutions that allow them to seamlessly move and analyze data across different cloud providers, avoiding vendor lock-in and optimizing costs.
These trends highlight the dynamic nature of cloud-native descriptive analytics. As technology continues to evolve, we can expect even more innovative and powerful solutions that empower organizations to gain deeper insights, automate processes, and make real-time decisions based on data.
Conclusion
Cloud-native solutions have transformed the landscape of descriptive analytics, empowering organizations to gain valuable insights from their data with unprecedented speed, scale, and cost- efficiency. By leveraging cloud-based data storage, processing, orchestration, and visualization tools, businesses can unlock the full potential of their data and make informed decisions that drive growth and success.
The architectural components of cloud-native solutions, such as data lakes, data warehouses, data lakehouses, serverless computing, and managed services, provide the foundation for efficient and scalable descriptive analytics. Cloud-based BI tools further enhance the ability to explore, analyze, and communicate insights effectively.
The benefits of cloud-native descriptive analytics are manifold. They include scalability and elasticity to handle growing data volumes, cost-efficiency through pay-as-you-go pricing and reduced infrastructure costs, agility and accessibility for faster data exploration, collaboration across teams and locations, and reliability and security through built-in cloud features.
While cloud-native solutions offer numerous advantages, organizations must address challenges related to data quality, security, performance optimization, and skills development. By adhering to best practices such as data governance, automation, cost optimization, and continuous learning, businesses can ensure the successful implementation and ongoing optimization of their cloud-native descriptive analytics capabilities.
Looking ahead, the future of descriptive analytics in the cloud is bright. Emerging trends like serverless analytics, AI-augmented analytics, real-time analytics, and edge analytics promise to further enhance the capabilities and impact of cloud-native descriptive analytics.
In conclusion, cloud-native solutions have redefined the way organizations approach descriptive analytics. By embracing these solutions and adhering to best practices, businesses can harness the power of their data to gain valuable insights, make informed decisions, and thrive in today's data-driven world.
Glossary of Terms
- Cloud-Agnostic: Refers to solutions or technologies that are designed to work seamlessly across multiple cloud providers,avoiding vendor lock-in.
- Cloud-Native: Refers to applications or solutions that are built specifically for cloud environments, leveraging cloud- native technologies and design principles.
- Descriptive Analytics: A type of data analysis that focuses on understanding past trends and patterns by summarizing and visualizing historical data.
- DataLakes: Centralized repositories for storing vast amounts of structured, semi-structured, and unstructured data.
- Data Warehouses: Optimized for storing and querying structured data, enabling efficient data exploration and
- Data Lakehouses: Combine the best features of data lakes and data warehouses, offering a unified platform for storing and analyzing diverse data types.
- Business Intelligence (BI): Encompasses a set of tools and techniques for transforming raw data into meaningful and actionable insights.
- ServerlessComputing: Allows for on-demand execution of code without the need for managing servers.
- Edge Computing: Involves processing and analyzing data closer to the source, at the edge of the network.
- Infrastructure as Code (IaC): The practice of managing and provisioning infrastructure through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools
- Batch Processing: Processing large volumes of data in a scheduled or non-continuous manner.
- Stream Processing: Processing data in real-time or near- real-time as it arrives in a continuous stream.
- Time Series Analytics: Analyzing data points collected at regular intervals over time to identify trends, seasonality, and other patterns.
References
- Han J, Kamber , Pei J (2011) Data mining: concepts and techniques Elsevier.
- Dean J, Ghemawat S (2008) MapReduce: simplified data processing on large clusters. Communications of the ACM 51: 107-111
- Abadi DJ, Agarwal A, Barham P, Brevdo E, Chen Z, et al. (2016) TensorFlow: A system for large-scale machine In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) 265-283.
- Baldini G, Castro P, Lange K, Zdun U (2018) Serverless computing: Current trends and open In Proceedings of the 3rd International Workshop on Serverless Computing 1-6.
- Pearson S (2016) Data governance in the cloud: The essential guide for business success. John Wiley & Sons.
- RightScale (2019) 2019 State of the Cloud Retrieved from [invalid URL removed]
View PDF