Author(s): Vijay Kartik Sikha
Site Reliability Engineering (SRE) is a modern practice that merges software engineering and IT operations to ensure highly reliable, scalable, and efficient systems at scale. Originally developed at Google in the mid-2000s, SRE places a strong emphasis on reliability, scalability, and efficiency, aiming to create self-managing and self-healing systems. This approach fosters a culture of safety, shared responsibility, continuous learning, and a blame-free environment. Key focus areas within SRE include observability, operations at scale, security, resilience, and cloud-agnostic requirements. SRE leverages automation, AI, and ML to enhance system robustness and proactive issue management. As SRE practices evolve, they are proving to be essential for various industries, such as finance, healthcare, and e-commerce, by offering improved service availability, reduced incident handling time, and promoting environmental sustainability. Future growth areas for SRE include edge computing, AI/ML integration, and managing hybrid and multi-cloud environments. Strong SRE teams, supported by tools and frameworks from cloud providers, bring significant value to organizations by improving user experience, increasing revenue streams, and maintaining the company's reputation.
Site Reliability Engineering (SRE) is a transformative approach that combines software engineering and IT operations to build and run scalable, reliable systems. Initially pioneered by Google, SRE has become a critical practice for organizations aiming to maintain high availability and performance in their IT infrastructure [1].
SRE focuses on enhancing the reliability, scalability, and efficiency of systems. The ultimate goal is to create self-managing and self- healing systems, minimizing the need for human intervention. This approach has gained significant traction in recent years, extending beyond major tech companies to organizations of all sizes [1].
To lay a strong foundation for understanding SRE, it’s essential to grasp its core concepts:
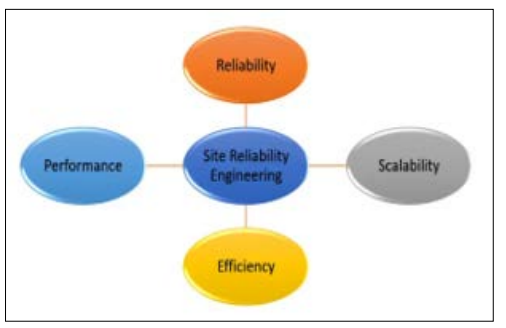
Figure 1: SRE Characteristics
SRE, or Site Reliability Engineering, focuses on establishing a culture of safety with shared responsibility, continuous learning, and a blame-free approach to mistakes made by developers, operators, and testers. It involves defining and monitoring metrics, working closely with or even enforcing SLAs (Service Level Agreements), and embracing the management of failures as a constructive aspect [2]. SRE also helps organizations achieve a balance between rapid feature releases and consistent, reliable service delivery to users [2].
Looking at the history of SRE helps in comprehending the general principles of guidance and the philosophy behind it. SRE was first developed at Google in mid-2000s to eliminate its growing pains of managing and running large online services such as Search, Maps, and Gmail [2]. When these platforms grew at an exponential rate, it became increasingly unmanageable to apply conventional styles of managing IT operations, resulting in subsequent downtimes, expensive outages and disgruntled users [2]. To address these issues, Google introduced SRE as a scientific and mathematical methodology for providing availability, latency, performance, and capacity.
SRE, or Site Reliability Engineering, has emerged as a crucial aspect of modern IT operations as organizations shift towards cloud technologies, microservices, and containerization. SRE provides a robust model to address the complexities of modern IT environments, offering solutions for multi-cloud observability and security, microservices management, and automation. These capabilities enable SRE teams to promptly diagnose and resolve issues, ensuring minimal impact on end users and maintaining high system resilience [3].
Given the continued growth of technology and increasing pressure on modern IT, SRE has become more essential than ever. It is invaluable for global organizations aiming to improve service availability, reduce incident handling time, and extend mean time between failures (MTBF). Moreover, SRE's capacity to reduce resource utilization and power usage is beneficial for businesses striving to minimize their carbon footprint, aligning with the growing focus on environmental sustainability [3].
To become a Site Reliability Engineer, the employee needs to be proficient in several domains, which are tactical and technical [4]. Amongst those, five primary areas stand out as foundational pillars underpinning successful SRE practice: Visibility, Scalability, Protection, Business Problems/WoT Recovery, and Multi-Cloud Constraints. Exploring these spheres further describes how they enhance the dependability of systems, promote easy fault identification, improve cyber protection, ensure failover capability, and facilitate cloud portability [5].
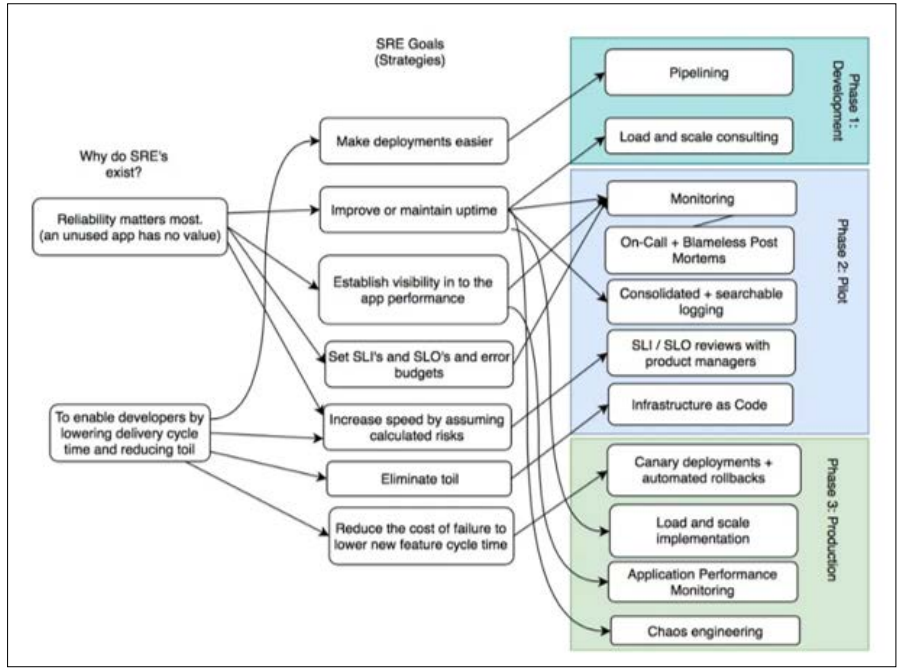
Figure 2: Building SRE from Scratch [6]
Site Reliability Engineering (SRE) has its roots in making comprehensive monitoring, logging, and tracing essential components of the processes. These three elements—metrics, logs, and traces—are the key pillars of observability, providing deep insights into system performance and behavior.
Metrics: Metrics involve the collection of quantitative data over time, such as CPU usage, memory consumption, and network traffic. These metrics help in understanding the system’s health and performance in a concise manner.
Logs: Logging captures significant activities within a system, providing a detailed record of events. This is crucial for post- incident analysis and general audits, helping teams understand what happened and why [5].
Traces: Tracing is particularly important in distributed architectures. It tracks requests as they flow through various components, allowing engineers to analyze interactions and pinpoint issues across the entire stack. Tracing frameworks like Zipkin, Jaeger, and OpenTelemetry are commonly used to enhance observability [7]. Tracing helps in understanding the complex interactions within a distributed system. By following the path of a request, tracing can reveal bottlenecks, latency issues, and failures, making it easier to diagnose and resolve problems quickly.
Efficient Incident Response: Robust observability practices and tools have significantly improved incident response mechanisms. With comprehensive metrics, logs, and traces, teams can quickly identify and diagnose issues, reducing downtime and improving system reliability. Tools like Prometheus, ELK Stack, and New Relic provide powerful capabilities for monitoring and analyzing telemetry data, enabling faster and more effective incident resolution [8].
By leveraging these observability practices, organizations can ensure their systems are not only reliable and efficient but also resilient to failures.
Mission-critical large systems are accompanied by numerous issues including a strong need for automating processes, effective solutions for addressing widespread incidents, and implementing sound capacity planning practices. The implementation of automation offers several benefits, such as the reduction of manual work in tasks that are repetitive in nature and the decreased likelihood of errors, as the work is completed through automation. Additionally, tasks are carried out more efficiently and swiftly. Crisis management communication flows outline guidelines for navigating crises, including step-by-step procedures, the responsibilities of various individuals, and insights derived from past incidents that can be applied in the future [5].
In today’s world filled with various threats, protecting assets is a top priority for any organization. In Site Reliability Engineering (SRE), this translates to stringent management of vulnerabilities, strict access control measures, and keen observance of regulatory standards [9].
Vulnerability Management: SRE practices involve frequent inspection of exposed surfaces for well-documented vulnerabilities, reinforcing points of susceptibility, and developing offsetting measures where immediate remedial action is not possible. This proactive approach helps in identifying and mitigating potential threats before they can be exploited.
Access Control: Access controls are crucial in reducing exposure to threats. SRE implements principles such as compartmentalization of duties, following the least privilege concept, denying unnecessary privileges, and employing robust authentication and authorization methods.
Observance of Regulatory Standards: Adhering to regulatory standards ensures that systems comply with legal and industry requirements, further enhancing security and reliability.
Improvement in Cyber Incident Prevention: Studies have shown that robust SRE practices significantly improve the prevention of cyber incidents. For example, Google’s incident response framework, which includes comprehensive monitoring, logging, and tracing, has been highly effective in managing and mitigating incidents [10]. By adopting these best practices, organizations can enhance their security posture and reduce the likelihood of cyber incidents.
Of all the aspects of SRE planning, assessing and considering potential catastrophic situations is an indispensable component. Business continuity involves developing plans to have contingency alternatives that are capable of supporting organization’s critical activities even when faced with challenges, while disaster recovery involves the ability to return the business to order in the aftermath of disasters [11]. Technical robustness can be naturally implemented to create systems that are naturally fault tolerant with the help of load balancing, sharding or horizontal scaling methods.
Creating SRE procedures that are easily adjustable to various contexts is crucial, especially in multi-cloud environments. This adaptability ensures that systems can be efficiently managed across different cloud platforms [11].
Several tools support applications running across multiple clouds, facilitating seamless integration and management:
Terraform: an open-source infrastructure as code tool that allows you to define and provision data center infrastructure using a high-level configuration language. It supports multiple cloud providers, making it easier to manage resources across different environments [12].
Kubernetes: an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Kubernetes can run on various cloud platforms, providing a consistent environment for applications [13].
Prometheus and Grafana: Prometheus is a monitoring tool that collects and stores metrics, while Grafana is used for visualizing these metrics. Both tools can be integrated with multiple cloud services to provide a unified view of system performance [14].
Ansible: an open-source automation tool that can manage configurations and deployments across different cloud environments. It uses simple, human-readable YAML files tautomate tasks [15].
Capacity Planning: It is essential for ensuring that systems can handle expected loads without performance degradation. Tools like Kubernetes help in managing resources efficiently by automatically scaling applications based on demand. For example, Kubernetes can scale up the number of pods running an application when traffic increases, ensuring that the system remains responsive [13].
Effective system performance management involves monitoring and optimizing the performance of applications and infrastructure. Tools like Datadog provide comprehensive visibility into system performance across multiple clouds. Datadog’s features include application performance monitoring (APM), log management, and infrastructure monitoring, which help in identifying and resolving performance bottlenecks [16].
By using these tools and practices, organizations can ensure that their SRE procedures are adaptable and effective in multi-cloud environments, leading to improved reliability and performance [11].
Adopting constrained SRE practices requires using purpose-built solutions to achieve the proposed main goals and objectives. Therefore, the key factors influencing the choice of relevant resources include the size of the organization, budget constraints for implementation, and the ease of integration [9].
Large entities often opt for feature-rich, highly expandable systems with extensive customization options that integrate seamlessly with their existing IT environments. Examples of such commercial solutions include ServiceNow, New Relic, and Datadog. These tools offer comprehensive functionality but can be costly and may not be the best fit for smaller organizations [9].
Prevalence of Open-Source Options - For small-scale companies and businesses, open-source tools provide a more affordable and efficient alternative. Tools like Nagios, Zabbix, and Elasticsearch are popular choices due to their cost-effectiveness, strong community support, and relatively simple setup processes [9].
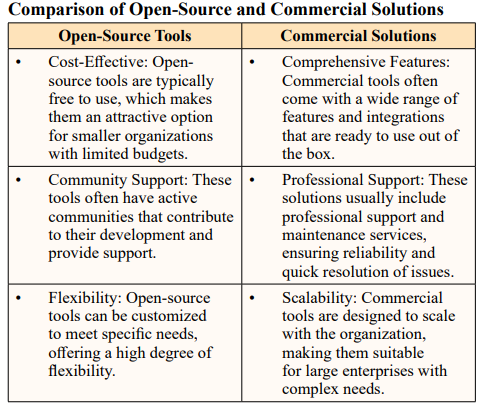
The basic set of instruments for SRE operations involves having monitoring and incident management tools that provide real-time signals, correlation, and a unified view of environments in large estates [9]. Popular solutions comprise Prometheus, Grafana, and PagerDuty, addressing distinct requirements:
Automation plays a key role in SRE practices, implemented through configuration management, infrastructure as code (IaC), and continuous deployment [9]. This domain is defined by various tools:
Despite the differences in understated infrastructure there are some common trends observed in SRE practice, relevant to automation, scalability, and reliability
The cloud provides various abstractions, among which are the possibilities of scaling and allocating or releasing capacity only as required. Auto-scaling can also set a range of instances automatically to adjust on its own while load balancer refines incoming requests ensuring that the load is split evenly. Self- healing capability allows failure-prone parts to self-repair without the need for manual intervention due to underlying hardware issues or temporary connectivity problems.
Using universal patterns such as circuit breakers, retries, and chaos engineering, improved resilience is achieved irrespective of cloud affiliation:
A fundamental concept in Site Reliability Engineering (SRE) is the use of automation to handle repetitive tasks, minimize human errors, and maintain consistency in setup and control. The integration of automation in SRE has evolved from reliance on human effort to systems featuring artificial intelligence, such as machine learning and analytics [17]. Key areas for SRE automation maturity include the effective and sustainable management of patches and configurations for updates within an organization.
In this context, SREs can achieve faster incident response times, make better decisions when using AI tools, and continually improve their skills. When human expertise, knowledge, and intuition are combined with artificial intelligence, organizations benefit from a faster problem-solving process, increased accuracy, and improved performance [17]. With the expansion of SRE, there is a growing focus on improving interaction and integration between humans and artificial intelligence, as well as addressing new challenges and ongoing issues in the development of more complex IT environments.
Google’s implementation of SRE practices provides a notable example. Google developed a comprehensive SRE maturity model to evaluate and improve their SRE practices. This model consists of five maturity levels: Chaotic, Reactive, Proactive, Managed, and Optimizing.
Consider a scenario where an organization uses AI-driven automation for incident response. When an issue is detected, the system automatically identifies the root cause, applies the necessary fixes, and notifies the SRE team. This reduces the mean time to resolution (MTTR) and allows the team to focus on more strategic tasks. For instance, Netflix employs a similar approach with its “Chaos Monkey” tool, which randomly disables production instances to ensure their systems can automatically handle failures without human intervention [18].
SRE practices contribute notably towards maximizing reliability in numerous large concern areas including financial, healthcare and e-commerce areas. In finance, SRE provides continuity to banking operations, trading platforms, and other financial management reporting units. It assists with the necessary regulations on practices and reduce risks associated with the exposure of important financial information. In the healthcare sector, SRE helps the essential medical appliances, records, telemedicine, and clinical trial solutions; it elevates the patient care quality and safety [9]. Many e-commerce businesses use SRE to maintain continuous availability, processing a vast amount of traffic and ensuring uninterrupted uptime during major sale events.
Furthermore, the principles of SRE are a perfect fit for attractive and dynamic industries including founders, who are focused on building agile customer-driven businesses in digital services spheres. In the context of their operations, such firms may need shorter time to market, the ability to scale up or down and efficient disaster recovery tools within constrained budgets [9]. These SRE methodologies help them focus and handle operational issues, decrease time to market, allocate resources properly and provide stability for growth. Lastly, implementing SRE allows regular businesses and digital-native companies to enhance the quality of their service and enhance security to adapt to changing market needs and demands.
Objective: Singlife, a reputable finance firm, aimed to enhance the reliability and performance of its diverse technical landscape. The primary goals were to reduce the mean time to recovery (MTTR), establish service level objectives, and improve visibility into system issues and outages.
Several areas of recent development in Site Reliability Engineering (SRE) are expected to see significant growth. Firstly, SRE's application in edge computing has become essential due to the rising use of distributed systems and the IoT [19]. This trend presents SRE professionals with new challenges related to latency, the network, and localized data processing. Secondly, the integration of AI and ML is being explored to provide great potential in enhancing various aspects of Big Data Analytics such as forecasts, exception detection, and autonomous remediations. Adopting these advanced approaches helps SRE teams to prevent problems and proactively address them to improve system robustness [17]. Finally, complexity arises when organizations adopt a hybrid and multi-cloud environment, leading to challenges related to consistency, compatibility, and standards. SREs need to solve issues related to different tooling, SLIs/SLOs, and data governance to function well across the organization and maintain consistent performance (Pandey & Mustafa, 2010)
Cloud Provider Tools/Frameworks Supporting SRE Organizations implementing Site Reliability Engineering (SRE) can reap significant benefits by leveraging the variety of tools and frameworks offered by different cloud providers such as AWS CloudWatch, Google Stackdriver, and Azure Monitor. Additionally, Kubernetes and service meshes play a critical role in SRE operations by facilitating container orchestration, managing microservices interactions, and enabling automatic scaling [17].
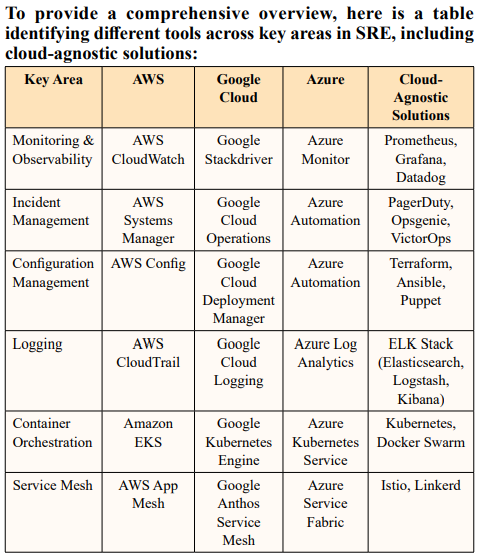
These tools and frameworks help SRE teams ensure system reliability, automate processes, and manage complex environments effectively.
Building a Site Reliability Engineering (SRE) team can bring significant value to an organization by improving the user experience, increasing sources of income, and upholding the company's image [20]. SREs collaborate closely with DevOps to ensure alignment and maintain iterative processes throughout the software development lifecycle [21]. This collaboration leads to continuous positive improvements, such as faster release cycles, reduced downtime, and increased user satisfaction. Moreover, skilled SRE teams can effectively address challenges in hybrid and multi-cloud environments, providing greater flexibility, portability, and interoperability across different IT environments [21]. A study highlights how modern SRE practices enable leaner teams to manage large-scale systems more efficiently compared to traditional operations from a decade ago. The study emphasizes that automation, proactive monitoring, and a focus on reliability engineering allow smaller teams to achieve higher operational efficiency and system reliability. [22-27].
In conclusion, Site Reliability Engineering (SRE) is crucial in modern IT processes, particularly in contemporary digital ecosystems where cloud solutions, microservices, and containerization are actively used. Successful SRE practice depends on five primary areas: visibility, scalability, protection, business continuity/WORF recovery, and multi-cloud governance. Management facilitated by monitoring, logging, and tracing, helps SREs address issues before they escalate. Managing operations at scale involves automation and handling crises in large complex systems. Vulnerability management, access control, and legal compliance are essential components of security management, which SRE effectively addresses. Developing technology measures and redundancy plans, as well as providing consultation to address continuity and recovery issues, is a critical aspect of ensuring business operations can resume as quickly and effectively as possible following a disruption. Multi-cloud strategies need to enforce cloud-independent policies to ensure compatibility and consistency across clouds. Site Reliability Engineering is maximized when SRE teams possess the appropriate tools and frameworks to perform additional work, utilizing the frameworks supplied by cloud providers. A positive outcome of a robust SRE team is the enhancement of user experience, the generation of additional revenue streams, and the preservation of the company's reputation.